



Java函数式编程
本文最后更新于 2025-08-17,文章内容可能已经过时。
Java函数式编程
第一章:函数对象
01、合格的函数
-
只要输入相同无论多少次输入,得到的结果都是一样的。
比如如下的例子:
package demo01; public class Sample01 { public static void main(String[] args) { System.out.println(square(5)); System.out.println(square(5)); System.out.println(square(5)); System.out.println(square(5)); System.out.println(square(5)); } static int square(int x){ return x * x; } }这个就是函数,因为你只要保证了输入是相同的,那么输出也就固定了。
那么在看看这个例子,这个也还是函数吗?
package demo01; public class Sample02 { static Buddha buddha = new Buddha("如来"); public static void main(String[] args) { System.out.println(pray("张三")); System.out.println(pray("张三")); System.out.println(pray("张三")); System.out.println(pray("张三")); System.out.println(pray("张三")); } static String pray(String person) { return person + "向" + buddha.name + "虔诚祈祷!"; } static class Buddha { String name; public Buddha(String name) { this.name = name; } } }答案:不是函数。原因在这里,看如下代码。
package demo01; public class Sample02 { static Buddha buddha = new Buddha("如来"); public static void main(String[] args) { System.out.println(pray("张三")); System.out.println(pray("张三")); buddha.name = "波旬"; System.out.println(pray("张三")); System.out.println(pray("张三")); } static String pray(String person) { return person + "向" + buddha.name + "虔诚祈祷!"; } static class Buddha { String name; public Buddha(String name) { this.name = name; } } }如果我在中途改变了祈祷对象的名字那么岂不是就不是向佛祖祈祷了?所有这不能保证我输入不变,输出就不变。
如果函数你的函数引用了外部的一个可变的变量,那么这个函数就不是合格的函数。其实就在外部的佛祖上加个final关键字即可。
如果使用的是JDK16及以上,可以使用record类来轻松实现这一效果:
package demo01; public class Sample03 { static Buddha buddha = new Buddha("如来"); public static void main(String[] args) { System.out.println(pray("张三")); System.out.println(pray("张三")); System.out.println(pray("张三")); System.out.println(pray("张三")); } static String pray(String person) { return person + "向" + buddha.name + "虔诚祈祷!"; } record Buddha(String name) { } } -
Java中方法与函数并无本质区别
比如如下代码:
package demo01; public class Sample04 { public static void main(String[] args) { Student student1 = new Student("张三"); System.out.println(student1.getName()); System.out.println(student1.getName()); Student student2 = new Student("李四"); System.out.println(student2.getName()); System.out.println(student2.getName()); } } class Student { final String name; public Student(String name) { this.name = name; } public String getName() { return name; } }其实等价于
package demo01; public class Sample04 { public static void main(String[] args) { Student student1 = new Student("张三"); System.out.println(student1.getName()); System.out.println(student1.getName()); Student student2 = new Student("李四"); System.out.println(student2.getName()); System.out.println(student2.getName()); } } class Student { final String name; public Student(String name) { this.name = name; } public String getName(Student this) { return this.name; } }即成员方法其实有个参数,即成员对象本身。
02、有形的函数
要想让函数有形,即把函数化为对象即可。比如如下代码
package demo01;
public class Sample05 {
// 普通函数
static int add(int a, int b) {
return a + b;
}
interface Lambda {
int calculate(int a, int b);
}
//函数化为对象
Lambda add = (a, b) -> a + b;
}
前者是纯粹的一个两数相加的法则,它的位置是固定的,如果要使用它,那么就需要通过Sample05.add找到它,然后执行。而后者(add对象)就像长了腿,它的位置是可以变化的,想去哪就去哪,哪里需要就可以去哪。而这里接口的目的是为了将来引用它来执行函数对象,此接口中只能有一个定义方法。
package demo01;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.net.ServerSocket;
import java.net.Socket;
import java.util.concurrent.ThreadLocalRandom;
public class Sample05 {
// 函数化为对象
static Lambda add = (a, b) -> a + b;
// 普通函数
static int add(int a, int b) {
return a + b;
}
interface Lambda extends Serializable {
int calculate(int a, int b);
}
static class Server {
public static void main(String[] args) throws IOException {
ServerSocket ss = new ServerSocket(8080);
System.out.println("启动服务器");
while (true) {
Socket s = ss.accept();
Thread.ofVirtual().start(() -> {
try {
ObjectInputStream ois = new ObjectInputStream(s.getInputStream());
Lambda lambda = (Lambda) ois.readObject();
int a = ThreadLocalRandom.current().nextInt(10);
int b = ThreadLocalRandom.current().nextInt(10);
System.out.printf("%s %d op %d = %d%n", s.getRemoteSocketAddress().toString(), a, b, lambda.calculate(a, b));
} catch (IOException | ClassNotFoundException e) {
throw new RuntimeException(e);
}
});
}
}
}
static class Client {
public static void main(String[] args) {
try (Socket socket = new Socket("localhost", 8080)) {
Lambda lambda = (a, b) -> a + b;
ObjectOutputStream oos = new ObjectOutputStream(socket.getOutputStream());
oos.writeObject(lambda);
oos.flush();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
}
}
03、函行为参数化
假设现在有一个学生的数组集合,需要你对其进行筛选过滤。传统的方法如何写呢?
package demo01;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.ArrayList;
import java.util.List;
@Data
@AllArgsConstructor
@NoArgsConstructor
class Student {
private String name;
private Integer age;
private String gender;
}
public class Sample06 {
public static void main(String[] args) {
List<Student> students = List.of(
new Student("张三", 16, "男"),
new Student("李四", 18, "女"),
new Student("王五", 18, "男")
);
/*
* 筛选男生
* */
System.out.println(filter(students));
}
static List<Student> filter(List<Student> students) {
List<Student> result = new ArrayList<>();
for (Student student : students) {
if (student.getGender().equals("男")) {
result.add(student);
}
}
return result;
}
}
这样就可以筛选出男生了,但是如果我又要筛选出年龄小于18的,那岂不是还得写一个方法,而且这个方法和刚刚的filter方法还高度相似。对于这个情况,我们就可以使用,行为参数化,直接上代码:
package demo01;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.ArrayList;
import java.util.List;
interface Lambda {
boolean test(Student student);
}
@Data
@AllArgsConstructor
@NoArgsConstructor
class Student {
private String name;
private Integer age;
private String gender;
}
public class Sample06 {
public static void main(String[] args) {
List<Student> students = List.of(
new Student("张三", 16, "男"),
new Student("李四", 18, "女"),
new Student("王五", 18, "男")
);
/*
* 筛选男生
* */
// System.out.println(filter(students));
System.out.println(filter(students, student -> student.getGender().equals("男")));
/*
* 筛选年龄小于18
* */
System.out.println(filter(students, student -> student.getAge() < 18));
}
static List<Student> filter(List<Student> students, Lambda lambda) {
List<Student> result = new ArrayList<>();
for (Student student : students) {
if (lambda.test(student)) {
result.add(student);
}
}
return result;
}
}
我们通过定义一个接口,接口添加加一个方法,这个方法名字随便起,但主要其参数和返回值,拿这个地方举例,我们需要筛选学生,那么传入的参数就是学生对象,筛选条件的返回值是符合或不符合,那么就是boolean类型。接着我们在filter方法添加一个参数,添加我们刚刚定义的接口。当我们主方法调用这个filter方法的时候,需要传入该方法的具体实现。也就做到了定义一个filter方法,但是我们筛选条件可以有变化。
04、延迟执行
延迟执行的意思其实是说在不同的条件下,代码执行的的情况可能不同,比如以下代码:
package com.hanserwei.day1;
import org.apache.logging.log4j.Level;
import org.apache.logging.log4j.LogManager;
import org.apache.logging.log4j.Logger;
import org.apache.logging.log4j.core.appender.ConsoleAppender;
import org.apache.logging.log4j.core.config.Configurator;
import org.apache.logging.log4j.core.config.builder.api.AppenderComponentBuilder;
import org.apache.logging.log4j.core.config.builder.api.ConfigurationBuilder;
import org.apache.logging.log4j.core.config.builder.api.ConfigurationBuilderFactory;
import org.apache.logging.log4j.core.config.builder.impl.BuiltConfiguration;
// 函数对象好处2:延迟执行
public class Sample7 {
static Logger logger = init(Level.DEBUG);
public static void main(String[] args) {
/*if (logger.isDebugEnabled()) {
logger.debug("{}", expensive());
}*/
logger.debug("{}", expensive()); // expensive() 立刻执行
logger.debug("{}", () -> expensive()); // 函数对象使得 expensive 延迟执行
}
static String expensive() {
System.out.println("执行耗时操作...");
return "日志";
}
static Logger init(Level level) {
ConfigurationBuilder<BuiltConfiguration> builder = ConfigurationBuilderFactory.newConfigurationBuilder()
.setStatusLevel(Level.ERROR)
.setConfigurationName("BuilderTest");
AppenderComponentBuilder appender =
builder.newAppender("Stdout", "CONSOLE")
.addAttribute("target", ConsoleAppender.Target.SYSTEM_OUT)
.add(builder.newLayout("PatternLayout").addAttribute("pattern", "%d [%t] %-5level: %msg%n%throwable"));
builder.add(appender)
.add(builder.newRootLogger(level).add(builder.newAppenderRef("Stdout")));
Configurator.initialize(builder.build());
return LogManager.getLogger();
}
}
改变logger的日志级别,你会发现第二个只会在debug的时候执行,而一个无论你是啥级别都会执行。具体实现原理可以点进源码字节阅读。其实就是如果传入的是个函数对象,那么内部就会判断是否需要执行。从而达到延迟执行的目的。
第二章
01、函数对象表现形式
函数对象的表现形式有两种,即lambda表达式和方法引用
-
lambda表达式
(int a, int b) -> a + b;注意在定义参数的时候要明确定义参数的类型
(int a, int b) -> { int c = a + b; return c;}如果逻辑部分,代码多于一行,那么不能省略
{}以及最后一行的return(a, b) -> a + b;当上下文代码可推导出
a和b的类型的时候,那么在参数定义的时候这个,参数的类型就可以省略不写。比如如下情况:Lambda1 lambda = (a, b) -> a + b; interface Lambda1 { int op(int a, int b); }在这个例子中,我们已经知道这个函数对象的类型是
Lambda1类型,那么在接口Lambda1中可有推导出a和b的类型是int。a -> a;当只要一个参数的时候,那么参数两边的
()也可以省略。 -
方法引用
Math::max左侧是类名,中间
::,右边是类中的一个静态方法。与之对应的
Lambda表达式如下:(int a, int b) -> Math.max(a, b);再看下一个例子
Student::getName左侧是一个对象,右侧是对象的非静态方法,等价于
(Student stu) -> stu.getName这里要获取学生的姓名,需要一个学生对象作为参数
System.out::println左侧是对象,右侧对象的非静态方法名。为了执行这个方法,缺少什么,缺少的就是需要打印的对象,那么这个就等价于
(Object obj) -> System.out.println(obj);再来看最后一个例子
Student::new这个例子的左侧还是类型名,右侧是个
new关键字,那么这个就代表执行该对象的构造方法。所以就等价于() -> new Student()
02、函数对象类型
函数对象的分类:按照参数类型和返回值类型进行分类。
函数式接口:仅仅包含一个一个抽象方法,用@FunctionalInterface进行检查。
package com.hanserwei.day2;
import java.math.BigInteger;
import java.util.ArrayList;
import java.util.List;
import java.util.function.Function;
import java.util.function.IntBinaryOperator;
import java.util.function.IntPredicate;
import java.util.function.Supplier;
public class CategoryTest {
public static void main(String[] args) {
Type1 obj1 = a -> (a & 1) == 0;
Type1 obj2 = a -> BigInteger.valueOf(a).isProbablePrime(100);
Type2 obj3 = (a, b, c) -> a + b + c;
Type3 obj4 = (a, b) -> a - b;
Type3 obj5 = (a, b) -> a * b;
Type6<Student> obj6 = () -> new Student();
Type6<List<Student>> obj7 = () -> new ArrayList<Student>();
Type7<String, Student> obj8 = s -> s.getName();
Type7<Integer, Student> obj9 = s -> s.getAge();
}
@FunctionalInterface
interface Type1 {
boolean op(int a);
}
@FunctionalInterface
interface IntTernaryOperator {
int op(int a, int b, int c);
}
@FunctionalInterface
interface Type3 {
int op(int a, int b);
}
@FunctionalInterface
interface Type4 {
Student op();
}
@FunctionalInterface
interface Type5 {
List<Student> op();
}
@FunctionalInterface
interface Type6<T> {
T op();
}
@FunctionalInterface
interface Type7<O, I> {
O op(I input);
}
}
其实JDK内部有现成的函数式接口类型:
-
IntPredicate接口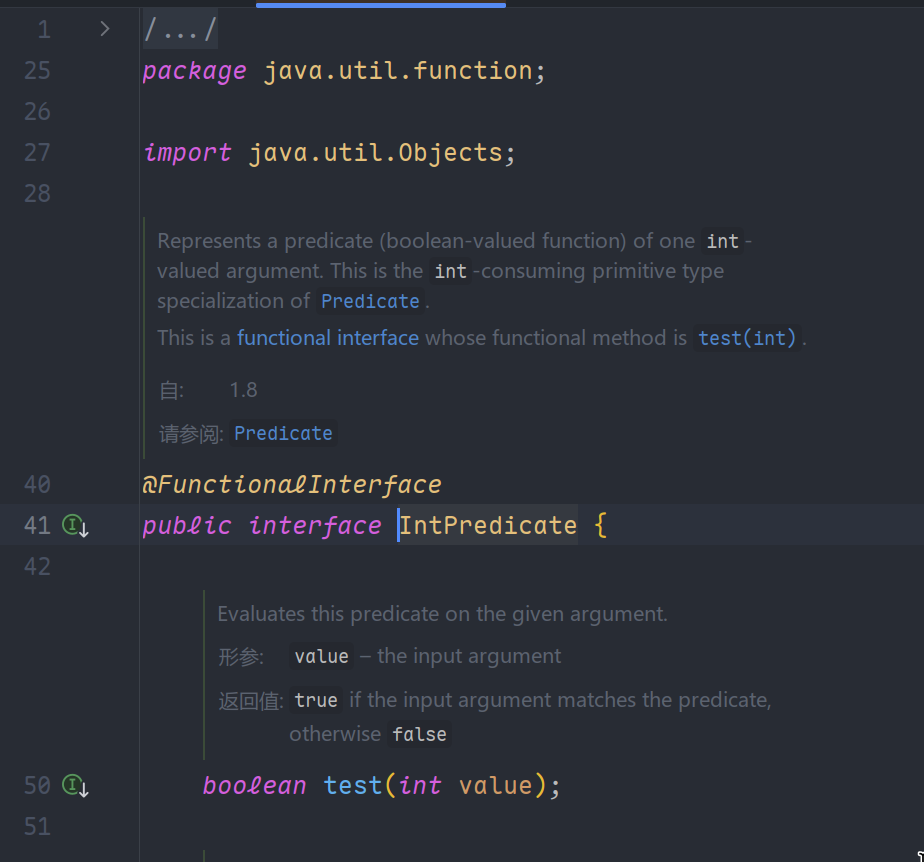
-
IntBinaryOperator接口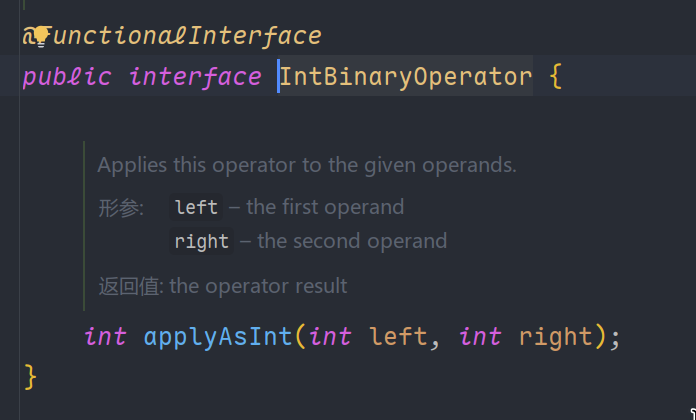
-
Supplier接口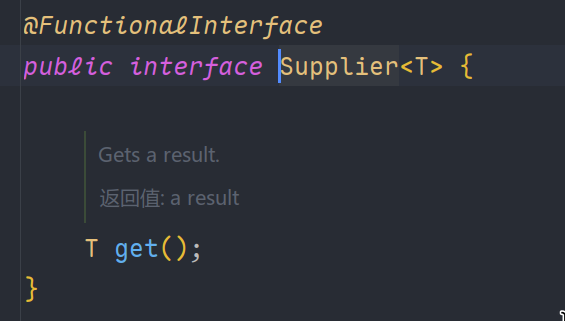
-
Function接口
所有绝大部分函数式接口JDK内都有定义,那么刚刚自定义的函数式接口就可以替换为如下代码
package com.hanserwei.day2; import java.math.BigInteger; import java.util.ArrayList; import java.util.List; import java.util.function.Function; import java.util.function.IntBinaryOperator; import java.util.function.IntPredicate; import java.util.function.Supplier; public class CategoryTest { public static void main(String[] args) { // Type1 obj1 = a -> (a & 1) == 0; // Type1 obj2 = a -> BigInteger.valueOf(a).isProbablePrime(100); // Type2 obj3 = (a, b, c) -> a + b + c; // Type3 obj4 = (a, b) -> a - b; // Type3 obj5 = (a, b) -> a * b; // Type6<Student> obj6 = () -> new Student(); // Type6<List<Student>> obj7 = () -> new ArrayList<Student>(); // Type7<String, Student> obj8 = s -> s.getName(); // Type7<Integer, Student> obj9 = s -> s.getAge(); IntPredicate obj1 = a -> (a & 1) == 0; IntPredicate obj2 = a -> BigInteger.valueOf(a).isProbablePrime(100); IntTernaryOperator obj3 = (a, b, c) -> a + b + c; IntBinaryOperator obj4 = (a, b) -> a - b; IntBinaryOperator obj5 = (a, b) -> a * b; Supplier<Student> obj6 = () -> new Student(); Supplier<List<Student>> obj7 = () -> new ArrayList<Student>(); Function<Student, String> obj8 = s -> s.getName(); Function<Student, Integer> obj9 = s -> s.getAge(); } @FunctionalInterface interface Type1 { boolean op(int a); } @FunctionalInterface interface IntTernaryOperator { int op(int a, int b, int c); } @FunctionalInterface interface Type3 { int op(int a, int b); } @FunctionalInterface interface Type4 { Student op(); } @FunctionalInterface interface Type5 { List<Student> op(); } @FunctionalInterface interface Type6<T> { T op(); } @FunctionalInterface interface Type7<O, I> { O op(I input); } static class Student { private String name; private String sex; private int age; public String getName() { return name; } public void setName(String name) { this.name = name; } public String getSex() { return sex; } public void setSex(String sex) { this.sex = sex; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } } -
常见的函数式接口
-
Runnable() -> void -
Callable() -> T -
Comparator(T, T) -> int -
Consumer,BiConsumer,IntConsumer,LongConsumer,DoubleConsumer(T) -> void, Bi是两参, Int指参数是 int有参数,无返回值。
-
Function,BiFunction,Int Long Double...(T) -> R, Bi是两参, Int指参数是 int -
Predicate,BiPredicate,Int Long Double...(T) -> boolean, Bi是两参, Int指参数是 int -
Supplier,Int Long Double...() -> T, Int指返回值是 int -
UnaryOperator,BinaryOperator,Int Long Double...(T) -> T, Unary 一参, Binary 两参, Int指参数是 int注意和
Function的区别,这个接口的返回值要和参数的类型一致。
总结:
名称 含义 Consumer 有参,无返回值 Function 有参,有返回值 Predicate 有参,返回 boolean Supplier 无参,有返回值 Operator 有参,有返回值,并且类型一样 前缀 含义 Unary 一元 Binary 二元 Ternary 三元 Quaternary 四元 ... ... -
03、方法引用
什么是方法引用,即将现有的方法调用转换为函数对象。
-
静态方法
(String s) -> Integer.parseInt(s)如果用方法引用就是
Integer::parseInt -
非静态方法
(stu) -> stu.getName()如果用方法引用则是
Student::getName -
构造方法
() -> new Student()用方法引用就是
Student::new
1、类名::静态方法
-
逻辑部分
就是执行此静态方法
-
参数部分
就是静态方法的参数
例子:
Math::abs的Lambda表达式为(n)->Math.abs(n)
Math::max的Lambda表达式为(a,b)->Math.max(a,b)
2、类名::非静态方法
-
逻辑部分
就是执行此非静态方法
-
参数部分
一是此类对象,一是非静态方法的参数
例子:
Student::getName的Lambda表达式(stu)->stu.getName()
Student::setName的Lambda表达式(stu,name)->stu.setName(name)
3、对象::非静态方法
-
逻辑部分
就是要去此对象的非静态方法
-
参数部分
就是非静态方法的参数
例子:
System.out::println的Lambda表达式为(obj)->System.out.println(obj)
注意与2的区别,2是类::非静态方法,那么不知是哪个对象在调用这个方法,所以需要有个对象作为参数。而3是对象::非静态方法,这个已经明确了是哪个对象,所有不需要再指定对象。
4、类名::new
-
逻辑部分
就是执行此构造方法
-
参数部分
就是构造方法的参数
例子:
Student::new的Lambda表达式为()->new Student()
Student::new的Lambda表达式为(name)->new Student(name)
构造方法可以重载,所有使用时要注意
package com.hanserwei.day2.methodref;
import java.util.function.BiFunction;
import java.util.function.Function;
import java.util.function.Supplier;
public class MethodRef4 {
static class Student {
private final String name;
private final Integer age;
public Student() {
this.name = "某人";
this.age = 18;
}
public Student(String name) {
this.name = name;
this.age = 18;
}
public Student(String name, Integer age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public static void main(String[] args) {
Supplier<Student> s1 = Student::new;
Function<String, Student> s2 = Student::new;
BiFunction<String, Integer, Student> s3 = Student::new;
System.out.println(s1.get());
System.out.println(s2.apply("张三"));
System.out.println(s3.apply("李四", 25));
}
}
即不同参数的构造方法,对应不同的函数对象。
5、this::非静态方法 与 super::非静态方法
这两个属于3的特例,在类的内部使用。
package com.hanserwei.day2.methodref;
import java.util.stream.Stream;
public class MethodRef5 {
public static void main(String[] args) {
// 改变父类实现,即可观察两种特殊的方法引用
Util util = new UtilExt();
util.hiOrder(Stream.of(
new Student("张无忌", "男"),
new Student("周芷若", "女"),
new Student("宋青书", "男")
));
}
record Student(String name, String sex) {
}
static class Util {
private boolean isMale(Student stu) {
return stu.sex().equals("男");
}
protected boolean isFemale(Student stu) {
return stu.sex().equals("女");
}
// 过滤男性学生并打印
void hiOrder(Stream<Student> stream) {
stream
// .filter(stu->this.isMale(stu))
.filter(this::isMale)
.forEach(System.out::println);
}
}
static class UtilExt extends Util {
// 过滤女性学生并打印
@Override
void hiOrder(Stream<Student> stream) {
stream.filter(super::isFemale)
.forEach(System.out::println);
}
}
}
小结:
不同方法引用的对比:
| 编号 | 格式 | 特点 | 备注 |
|---|---|---|---|
| 1 | 类名::静态方法 | 参数一致 | |
| 2 | 类名::非静态方法 | 参数多一个该类对象 | |
| 3 | 对象::非静态方法 | 参数一致 | |
| 4 | 类名::new | 参数一致 | |
| 5 | this::非静态方法 | - | 3特例,很少用 |
| 6 | super::非静态方法 | - | 3特例,很少用 |
特例:
对于无需返回值的函数式接口如
Consumer与Runable接口,它们可配合有返回值的函数对象使用。package com.hanserwei.day2.methodref; import java.util.function.Consumer; import java.util.function.Function; public class MethodRef7 { public static void main(String[] args) { Consumer<Object> x = MethodRef7::print1; Function<Object, Integer> y = MethodRef7::print2; Consumer<Object> z = MethodRef7::print2; } static void print1(Object obj) { System.out.println(obj); } static int print2(Object obj) { System.out.println(obj); return 1; } }
04、闭包和柯里化
闭包
-
闭包的定义:
package com.hanserwei.mydemo.closure; public class ClosureDemo01 { static void highOrder(Lambda lambda) { System.out.println(lambda.op(1)); } public static void main(String[] args) { int x = 10; highOrder((int y) -> x + y); } @FunctionalInterface interface Lambda { int op(int y); } }main函数里面,调用highOrder方法的时候,方法内的函数对象与外部的变量x绑定在一起了,这就是闭包。其中x这个变量可以是静态变量,成员变量,方法的参数变量。如下面代码所示:package com.hanserwei.mydemo.closure; public class ClosureDemo01 { static int a = 1; int b = 2; static void highOrder(Lambda lambda) { System.out.println(lambda.op(1)); } public static void main(String[] args) { int x = 10; highOrder((int y) -> x + y); } public static void test() { highOrder((int y) -> a + y); } public void test2() { highOrder((int y) -> b + y); } public void test3(int c) { highOrder((int y) -> c + y); } @FunctionalInterface interface Lambda { int op(int y); } }总的说来就是在函数对象的逻辑部分用到了外部变量那么就是闭包,但是对外部变量有一定的限制。
-
这个外部变量要是
final的或者effective final的,所谓effective final是指这个变量虽然没有加final关键字,但是这个变量没有被修改,可以看作是final的。package com.hanserwei.mydemo.closure; public class ClosureDemo02 { static void highOrder(Lambda lambda) { System.out.println(lambda.op(1)); } public static void main(String[] args) { int x = 10; highOrder((int y) -> x + y); //会报错!函数对象 (int y) -> x + y 与它外部的变量 x 形成了闭包。 // 那么这个x就必须是final的或者effect final的 x = 20; } @FunctionalInterface interface Lambda { int op(int y); } }注意:这里是指的是参与闭包的这个变量的栈地址不能发生改变,其内部还是可以发生改变的。比如如下代码:
package com.hanserwei.mydemo.closure; public class ClosureDemo03 { static void highOrder(ClosureDemo02.Lambda lambda) { System.out.println(lambda.op(1)); } public static void main(String[] args) { Student s = new Student(10); highOrder((int y) -> s.d + y); s.d = 20; } @FunctionalInterface interface Lambda { int op(int y); } static class Student { int d; public Student(int d) { this.d = d; } } }这里我改变了s内部的成员变量d的值,编译没有报错,说明Java对闭包的检测只检测到最外层。
-
闭包的作用:
-
给函数执行提供数据的手段
package com.hanserwei.mydemo.closure; import java.io.IOException; import java.util.ArrayList; import java.util.List; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; public class ClosureDemo04 { // 闭包的作用 public static void main(String[] args) throws IOException { // 创建10个任务对象,并且给每个任务对象一个任务编号 List<Runnable> list = new ArrayList<>(); for (int i = 0; i < 10; i++) { int k = i + 1; Runnable task = () -> System.out.println(Thread.currentThread()+":执行任务" + k); list.add(task); } ExecutorService service = Executors.newVirtualThreadPerTaskExecutor(); for (Runnable task : list) { service.submit(task); } System.in.read(); } }
柯里化
-
什么是柯里化?
package com.hanserwei.mydemo.currying; public class CarryingDemo01 { public static void main(String[] args) { // 两个参数的函数对象 F2 f = (a, b) -> a + b; System.out.println(f.op(10, 20)); /*改造:函数对象每次只能传入一个参数,要实现加法运算。将函数对象拆分成两个函数对象 * (a) -> 返回另一个函数对象 * (b) -> a + b * */ Fa fa = (a) -> (b) -> a + b; Fb fb = fa.op(10); int result = fb.op(20); System.out.println(result); } @FunctionalInterface interface F2 { int op(int a, int b); } @FunctionalInterface interface Fa { Fb op(int a); } @FunctionalInterface interface Fb { int op(int b); } }把具有多个参数的函数对象转换为多个只接收一个参数的函数对象,就叫柯里化。
-
实现柯里化
其实是结合闭包实现的,上述的例子中体现在:
Fa fa = (a) -> (b) -> a + b; -
柯里化的作用
-
本质作用是让函数分步执行。
package com.hanserwei.mydemo.currying; import java.util.ArrayList; import java.util.List; public class CarryingDemo02 { /* * 目标:把三份数据合在一起,逻辑既定,但数据不能一次得到。 * * a->函数对象 * b->函数对象 * c->函数对象 * */ static Fb step1() { List<Integer> x = List.of(1, 2, 3); Fa fa = a -> b -> c -> { List<Integer> list = new ArrayList<>(); list.addAll(a); list.addAll(b); list.addAll(c); return list; }; return fa.op(x); } static Fc step2(Fb fb) { List<Integer> y = List.of(4, 5, 6); return fb.op(y); } static void step3(Fc fc) { List<Integer> c = List.of(7, 8, 9); fc.op(c).forEach(System.out::println); } public static void main(String[] args) { // step3(step2(step1())); Fb fb = step1(); Fc fc = step2(fb); step3(fc); } @FunctionalInterface interface Fa { Fb op(List<Integer> a); } @FunctionalInterface interface Fb { Fc op(List<Integer> b); } @FunctionalInterface interface Fc { List<Integer> op(List<Integer> c); } }
-
05、高阶函数
所谓高阶函数,就是指它是其他函数对象的使用者。就如上面柯里化的例子里面的step1、step2、step3三个都可以称为高阶函数。
-
作用:
将通用、复杂的逻辑隐含在高阶函数里面,将易变、未定的逻辑放在高阶函数外部的函数对象中。
内循环
public class C01InnerLoop {
public static void main(String[] args) {
List<Integer> list = List.of(1, 2, 3, 4, 5, 6, 7);
// 需求:逆序遍历集合,只想负责元素处理,不改变集合
hiOrder(list, (value) -> System.out.println(value));
}
public static <T> void hiOrder(List<T> list, Consumer<T> consumer) {
ListIterator<T> iterator = list.listIterator(list.size());
while (iterator.hasPrevious()) {
T value = iterator.previous();
consumer.accept(value);
}
}
}
二叉树
package com.hanserwei.mydemo.currying;
import org.jetbrains.annotations.NotNull;
import java.util.function.Consumer;
public class BinaryTree {
public static void traversal2(TreeNode root, Type type, Consumer<TreeNode> consumer) {
if (root == null) {
return;
}
// 前序处理值
if (type == Type.PRE) {
consumer.accept(root);
}
traversal2(root.left, type, consumer);
// 中序处理值
if (type == Type.IN) {
consumer.accept(root);
}
traversal2(root.right, type, consumer);
// 后序处理值
if (type == Type.POST) {
consumer.accept(root);
}
}
public static void main(String[] args) {
/*
1
/ \
2 3
/ / \
4 5 6
前序 1 2 4 3 5 6 值左右
中序 4 2 1 5 3 6 左值右
后序 4 2 5 6 3 1 左右值
*/
TreeNode root = new TreeNode(1,
new TreeNode(2,
new TreeNode(4, null, null),
null
),
new TreeNode(3,
new TreeNode(5, null, null),
new TreeNode(6, null, null)
)
);
traversal2(root, Type.PRE, System.out::print);
System.out.println();
traversal2(root, Type.IN, System.out::print);
System.out.println();
traversal2(root, Type.POST, System.out::print);
System.out.println();
}
enum Type {
PRE, IN, POST
}
public record TreeNode(int value, TreeNode left, TreeNode right) {
@Override
@NotNull
public String toString() {
return "%d".formatted(value);
}
}
}
这里有个注意点,我这里使用的是递归便利,但是如果树太深的话,我们这个方法压栈的方式容易栈溢出,为了解决它,我们考虑非递归遍历的方式。
public static void traversal(TreeNode root, Type type, Consumer<TreeNode> consumer) {
// 用来记住回去的路
LinkedList<TreeNode> stack = new LinkedList<>();
// 当前节点
TreeNode curr = root;
// 记录最近一次处理完的节点
TreeNode last = null;
// 没有向左走到头或者还有未归的路
while (curr != null || !stack.isEmpty()) {
// 左边未走完
if (curr != null) {
// 记住来时的路
stack.push(curr);
// ------------------ 处理前序遍历的值
if(type == Type.PRE) {
consumer.accept(curr);
}
// 下次向左走
curr = curr.left;
}
// 左边已走完
else {
// 上次的路
TreeNode peek = stack.peek();
// 没有右子树
if (peek.right == null) {
// ------------------ 处理中序、后序遍历的值
if(type == Type.IN || type == Type.POST) {
consumer.accept(peek);
}
last = stack.pop();
}
// 有右子树, 已走完
else if (peek.right == last) {
// ------------------ 处理后序遍历的值
if (type == Type.POST) {
consumer.accept(peek);
}
last = stack.pop();
}
// 有右子树, 未走完
else {
// ------------------ 处理中序遍历的值
if (type == Type.IN) {
consumer.accept(peek);
}
// 下次向右走
curr = peek.right;
}
}
}
}
简单流
模仿学过的Stream,实现自己的SimpleStream,提供基本的高阶函数如map,filter,forEach等。
package com.hanserwei.mydemo.hiorder;
import java.util.ArrayList;
import java.util.Collection;
import java.util.List;
import java.util.function.Consumer;
import java.util.function.Function;
import java.util.function.Predicate;
public class SimpleStream<T> {
private Collection<T> collection;
private SimpleStream(Collection<T> collection) {
this.collection = collection;
}
public static void main(String[] args) {
List<Integer> list = List.of(1, 2, 3, 4, 5, 6, 7);
SimpleStream.of(list)
.filter(value -> value % 2 == 0)
.map(value -> value * 2)
.forEach(System.out::println);
}
/**
* 从提供的集合创建一个新的 {@code SimpleStream} 实例。
*
* @param <T> 集合中元素的类型
* @param collection 用作 {@code SimpleStream} 源的集合
* @return 包含所提供集合元素的新 {@code SimpleStream} 实例
*/
public static <T> SimpleStream<T> of(Collection<T> collection) {
return new SimpleStream<>(collection);
}
/**
* 根据给定的谓词过滤流中的元素。
*
* @param predicate 用于测试元素是否应包含在结果中的谓词
* @return 一个包含满足谓词条件的元素的新 {@code SimpleStream} 实例
*/
public SimpleStream<T> filter(Predicate<T> predicate) {
List<T> result = new ArrayList<>();
for (T t : collection) {
if (predicate.test(t)) {
result.add(t);
}
}
return new SimpleStream<>(result);
}
/**
* 将流中的每个元素应用给定的函数进行转换。
*
* @param <U> 转换后元素的类型
* @param function 应用于每个元素的函数
* @return 一个包含转换后元素的新 {@code SimpleStream} 实例
*/
public <U> SimpleStream<U> map(Function<T, U> function) {
List<U> result = new ArrayList<>();
for (T t : collection) {
U u = function.apply(t);
result.add(u);
}
return new SimpleStream<>(result);
}
/**
* 对流中的每个元素执行给定的操作。
*
* @param consumer 对每个元素执行的操作
*/
public void forEach(Consumer<T> consumer){
for (T t : collection) {
consumer.accept(t);
}
}
}
简单流-化简
两个元素按照某规则合并为一个
合并规则:
- 两个元素挑小的
- 两个元素挑大的
- 两个元素相加
/**
* 使用提供的二元操作符对流中的元素进行归约操作。
*
* @param operator 用于合并元素的二元操作符
* @param o 归约操作的初始值
* @return 归约操作的结果
*/
public T reduce(BinaryOperator<T> operator, T o) { // o代表p的初值
T p = o; // 上次合并的结果
for (T t : collection) { // t 本次遍历的元素
p = operator.apply(p, t);
}
return p;
}
简单流-收集
提供一个新的容器(集合),将元素加入其中
收集规则:
- 用Set收集
- 用StringBuilder收集
- 用Map收集
/**
* 使用提供的供应商和消费者对流中的元素进行收集操作。
*
* @param <C> 收集容器的类型
* @param supplier 用于创建新的收集容器的供应商
* @param consumer 用于将元素添加到收集容器的消费者
* @return 包含所有流元素的收集容器
*/
public <C> C collect(Supplier<C> supplier, BiConsumer<C, T> consumer) {
C c = supplier.get();
for (T t : collection) {
consumer.accept(c, t);
}
return c;
}
第三章
在这一章,主要讲解Stream流API,Stream流API其实就是前面说的高阶函数,就是一堆Java现有的高阶函数。
Stream流-过滤
案例一:我这里有很多的浆果和坚果,那么我该如何快速把它们分类呢?这个时候你可能会说for循环。for循环可以,但是不够优雅,更优雅的做法应该是直接使用我们前面学过Predicate接口,直接完成分类。那么我们来看代码:
package com.hanserwei.mydemo.stream;
import java.util.stream.Stream;
record Fruit(String cname, String name, String category, String color) {
}
public class FilterTest {
public static void main(String[] args) {
Stream.of(
new Fruit("草莓", "Strawberry", "浆果", "红色"),
new Fruit("桑葚", "Mulberry", "浆果", "紫色"),
new Fruit("杨梅", "Waxberry", "浆果", "红色"),
new Fruit("核桃", "Walnut", "坚果", "棕色"),
new Fruit("花生", "Peanut", "坚果", "棕色"),
new Fruit("蓝莓", "Blueberry", "浆果", "蓝色")
)
.filter(f -> f.category().equals("浆果"))
.filter(f -> f.color().equals("蓝色"))
.forEach(System.out::println);
}
}
我们定义一个水果类,水果有它的中文名,英文名字,分类,颜色这几个属性。然后我们使用Stream.of方法构造一个流。接着对流进行处理。
f -> f.category().equals("浆果")我们取每个水果的对象,看它的分类是不是为浆果,如果是,那么就返回true,就保留,反之就舍弃!f -> f.color().equals("蓝色")同理,我们取每个水果对象,检查它的颜色是否为蓝色,如果符合就保留,反之舍弃。
输出结果:

这里的filter方法它的参数其实就是一个Predicate接口,即:接收一个参数,返回一个布尔值。
Stream流-映射
刚学完MyBatis对映射应该还比较了解,其实就是把一个对象转换为另一个对象,那么很容易联想到哪个接口?没错,就是Function接口。所有Stream的map方法就是传入的一个Function接口。我们也直接看代码,还是刚刚的水果例子,我现在想把那些水果打成酱:
package com.hanserwei.mydemo.stream;
import java.util.stream.Stream;
public class MapTest {
public static void main(String[] args) {
Stream.of(
new Fruit("草莓", "Strawberry", "浆果", "红色"),
new Fruit("桑葚", "Mulberry", "浆果", "紫色"),
new Fruit("杨梅", "Waxberry", "浆果", "红色"),
new Fruit("核桃", "Walnut", "坚果", "棕色"),
new Fruit("花生", "Peanut", "坚果", "棕色"),
new Fruit("蓝莓", "Blueberry", "浆果", "蓝色")
)
.filter(fruit -> fruit.category().equals("浆果"))
.map(fruit -> new fruitJam(fruit.name()))
.forEach(System.out::println);
}
record fruitJam(String name) {
}
}
注意:这样如果你想直接改水果的名称,是不行的。原因有两点:
- 我的水果是record类,没有set方法。
- 就算你是普通的class类,也不可以。因为
Function需要的是一个对象,返回的也是一个对象。
在本例中:我们先把浆果过滤出来,然后用map取每个浆果的名字,然后新构造一个果酱对象返回。最好打印输出。输出结果如下:
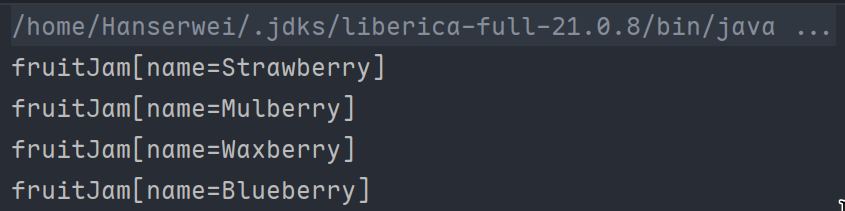
Stream流-扁平化(降维)
之所以叫叫降维,其实也好理解,如下图所示:
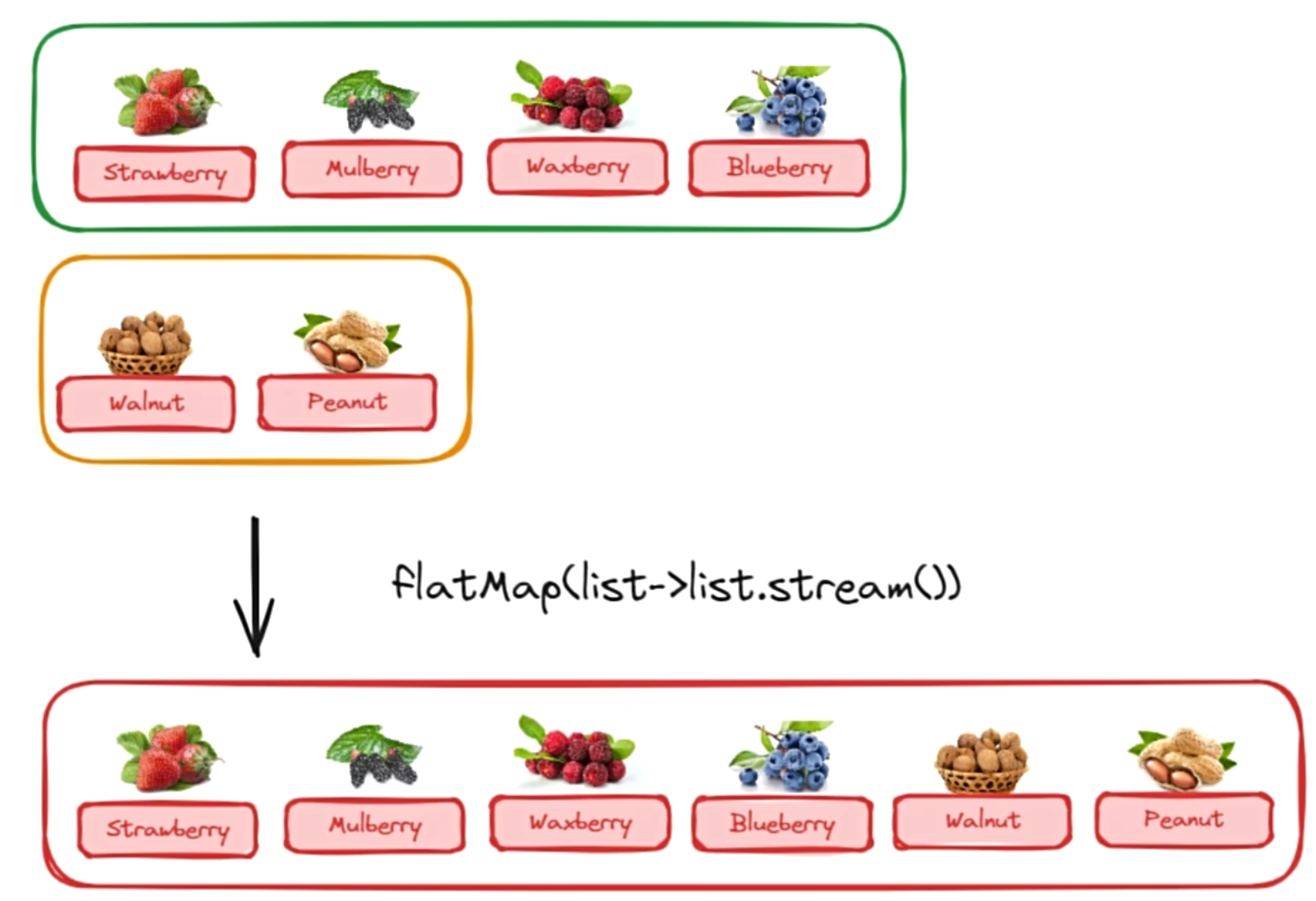
这个流中,有两个集合,每个集合有一些水果,然后我想把变一个只有水果的流,那么通过flatMap就可以很好的实现。这个方法传入的也是Function接口,我们需要做的就是把每个集合变成一个小的流,然后小流就可以汇入大流了。我们来看代码:
package com.hanserwei.mydemo.stream;
import java.util.Collection;
import java.util.List;
import java.util.stream.Stream;
public class FlatMapTest {
public static void main(String[] args) {
Stream.of(
List.of(
new Fruit("草莓", "Strawberry", "浆果", "红色"),
new Fruit("桑葚", "Mulberry", "浆果", "紫色"),
new Fruit("杨梅", "Waxberry", "浆果", "红色"),
new Fruit("蓝莓", "Blueberry", "浆果", "蓝色")
),
List.of(
new Fruit("核桃", "Walnut", "坚果", "棕色"),
new Fruit("草莓", "Peanut", "坚果", "棕色")
)
)
.forEach(System.out::println);
}
record Fruit(String cname, String name, String category, String color) {
}
}
我们刚开始,我们流有两个集合,每个集合又有一些水果。如果我们不做处理,直接打印会如何呢?

显然输出的是原始流中的元素,也就是两个集合。那么如果我们在打印之前加入一行代码
package com.hanserwei.mydemo.stream;
import java.util.Collection;
import java.util.List;
import java.util.stream.Stream;
public class FlatMapTest {
public static void main(String[] args) {
Stream.of(
List.of(
new Fruit("草莓", "Strawberry", "浆果", "红色"),
new Fruit("桑葚", "Mulberry", "浆果", "紫色"),
new Fruit("杨梅", "Waxberry", "浆果", "红色"),
new Fruit("蓝莓", "Blueberry", "浆果", "蓝色")
),
List.of(
new Fruit("核桃", "Walnut", "坚果", "棕色"),
new Fruit("草莓", "Peanut", "坚果", "棕色")
)
)
.flatMap(Collection::stream)
.forEach(System.out::println);
}
record Fruit(String cname, String name, String category, String color) {
}
}
我们再来看看输出:
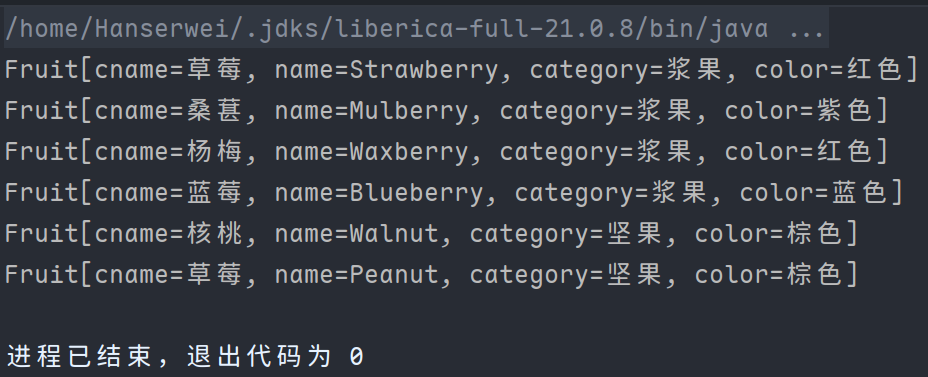
可以看到输出的是每个水果对象,那么就从原来的二维变成流一维。
再看一个例子:
package com.hanserwei.mydemo.stream;
import java.util.Arrays;
public class FlatMapTest2 {
public static void main(String[] args) {
Integer[][] array2D = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9},
};
Arrays.stream(array2D).forEach(System.out::println);
}
}
如果不降维,那么我们得到的输出就是三个一维数组,而且一维数组的toString方法没有重写。会得到类似于下面的输出:
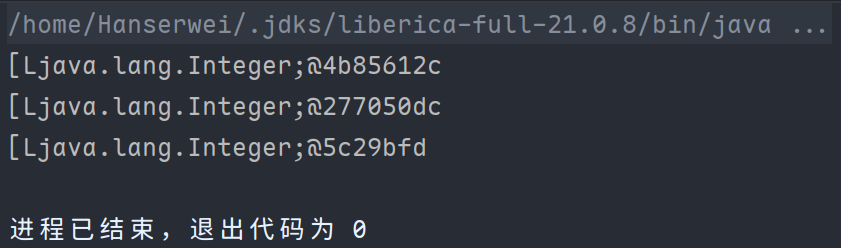
如果我们加上flatMap操作,结果如何呢?
package com.hanserwei.mydemo.stream;
import java.util.Arrays;
public class FlatMapTest2 {
public static void main(String[] args) {
Integer[][] array2D = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9},
};
Arrays.stream(array2D)
.flatMap(Arrays::stream)
.forEach(System.out::print);
}
}
输出结果是:

构建流
用已有的数据,构建出Stream对象。
从集合构建
可以通过集合.stream()直接获得流。
public class BuildStreamTest1 {
public static void main(String[] args) {
//1.从集合构建
List.of(1, 2, 3).stream().forEach(System.out::println);
}
}
这个
stream方法定义在Collection接口中,所有只要是Collection及其实现类都可以通过这个stream方法构建流。所有显然Map不能直接调用stream来获得流。但是别急也有办法。package com.hanserwei.mydemo.stream; import java.util.Map; public class BuildStreamTest2 { public static void main(String[] args) { // 1.构建Map Map.of("a", 1, "b", 2, "c", 3) .entrySet() .stream() .forEach(System.out::println); } }可以先调用
entrySet把map变成Set集合,然后就可以调用stream来获得流了。属于是曲线救国,但还是救了。
从数组构建
可以通过Arrays.stream(数组)直接获得流,这个简单不多说。
package com.hanserwei.mydemo.stream;
import java.util.Arrays;
public class BuildStreamTest3 {
public static void main(String[] args) {
// 1.数组构建流
int[] array = {1, 2, 3, 4, 5};
Arrays.stream(array).forEach(System.out::println);
}
}
从对象构建
可以使用Stream.of(对象)获取流。
package com.hanserwei.mydemo.stream;
import java.util.stream.Stream;
public class BuildStreamTest4 {
public static void main(String[] args) {
// 1.对象构建流
Stream.of("a", "b", "c").forEach(System.out::println);
}
}
这个也简单,直接过。
流的合并与截取
合并
顾名思义就是把两个流合并为一个流。,我们直接看代码:
package com.hanserwei.mydemo.stream;
import java.util.stream.Stream;
public class ConcatTest1 {
public static void main(String[] args) {
//1.合并
Stream<Integer> a = Stream.of(1, 2, 3);
Stream<Integer> b = Stream.of(4, 5, 6);
Stream.concat(a, b).forEach(System.out::print);
}
}
截取
-
直接给出截取位置
skip(long n)跳过n个数据,保留剩下的数据limit(long n)保留n个数据,剩余的数据不要
直接看代码:
package com.hanserwei.mydemo.stream; import java.util.stream.Stream; public class SplitTest1 { public static void main(String[] args) { //1.合并 Stream<Integer> a = Stream.of(1, 2, 3); Stream<Integer> b = Stream.of(4, 5, 6); Stream<Integer> stream = Stream.concat(a, b); /* * 1.截取---直接给出截取位置 * skip(long n) 跳过前n个元素,保留剩下的元素 * limit(long n) 截取前n个元素,剩余的元素丢弃 * */ stream.skip(2).forEach(System.out::print); } }输出结果如下:
3456如果使用
limit(long n)的话:package com.hanserwei.mydemo.stream; import java.util.stream.Stream; public class SplitTest1 { public static void main(String[] args) { //1.合并 Stream<Integer> a = Stream.of(1, 2, 3); Stream<Integer> b = Stream.of(4, 5, 6); Stream<Integer> stream = Stream.concat(a, b); /* * 1.截取---直接给出截取位置 * skip(long n) 跳过前n个元素,保留剩下的元素 * limit(long n) 截取前n个元素,剩余的元素丢弃 * */ stream.limit(2).forEach(System.out::print); } }输出:
12如果把两者结合起来使用,那么就可以截取中间的部分:
package com.hanserwei.mydemo.stream; import java.util.stream.Stream; public class SplitTest1 { public static void main(String[] args) { // 1.合并 Stream<Integer> a = Stream.of(1, 2, 3); Stream<Integer> b = Stream.of(4, 5, 6); Stream<Integer> stream = Stream.concat(a, b); /* * 1.截取---直接给出截取位置 * skip(long n) 跳过前n个元素,保留剩下的元素 * limit(long n) 截取前n个元素,剩余的元素丢弃 * */ // 截取中间3,4,5 Stream.of(1, 2, 3, 4, 5, 6).skip(2).limit(3).forEach(System.out::print); } }输出:
345 -
根据条件确定截取位置
takeWhile(Predicate p)条件成立保留,一旦条件不成立,就直接截断dropWhile(Predicate p)条件成立舍弃,一旦条件不成立,剩下的保留
还是直接看代码:
package com.hanserwei.mydemo.stream; import java.util.stream.Stream; public class SplitTest2 { public static void main(String[] args) { // 1.合并 Stream<Integer> a = Stream.of(1, 2, 3); Stream<Integer> b = Stream.of(4, 5, 6); Stream<Integer> stream = Stream.concat(a, b); /* * 2.截取---根据条件确定截取位置 * takeWhile(Predicate p) 截取满足p的元素,一旦条件不成立,剩余的元素丢弃 * dropWhile(Predicate p) 截取不满足p的元素,一旦条件不成立,剩余的元素保留 * */ stream.takeWhile(i -> i < 5).forEach(System.out::print); } }输出:
1234因为元素
5不满足条件,所有从5开始后面的元素都舍弃。同理,看
dropWhile运行效果:package com.hanserwei.mydemo.stream; import java.util.stream.Stream; public class SplitTest2 { public static void main(String[] args) { // 1.合并 Stream<Integer> a = Stream.of(1, 2, 3); Stream<Integer> b = Stream.of(4, 5, 6); Stream<Integer> stream = Stream.concat(a, b); /* * 2.截取---根据条件确定截取位置 * takeWhile(Predicate p) 截取满足p的元素,一旦条件不成立,剩余的元素丢弃 * dropWhile(Predicate p) 截取不满足p的元素,一旦条件不成立,剩余的元素保留 * */ stream.dropWhile(i -> i < 4).forEach(System.out::print); } }输出:
456因为元素
1、2以及3都是满足条件的,所有舍弃,当遇到元素4的时候,条件不满足,所以后面的元素全部保留!注意:
takeWhile(Predicate p)和dropWhile(Predicate p)只会检查到不满足条件为止,在不满足条件的元素出现之后,就不再起作用流,意思就是说对之后的元素不会在有过滤作用。注意与filter做区别。
生成流
不用现有的数据生成Stream流对象
简单生成
IntStream.range(...),注意这里是IntStream中的range方法,这个范围,也是左闭右开的。
package com.hanserwei.mydemo.stream;
import java.util.stream.IntStream;
public class GenerateTest1 {
public static void main(String[] args) {
//1.IntStream.range
IntStream.range(1, 10).forEach(System.out::print);
}
}
输出:
123456789
IntStream也有一个左闭右闭的方法rangeClose(),来看实例代码:
package com.hanserwei.mydemo.stream;
import java.util.stream.IntStream;
public class GenerateTest1 {
public static void main(String[] args) {
//1.IntStream.rangeClose
IntStream.rangeClosed(1, 9).forEach(System.out::print);
}
}
输出:
123456789
依赖上一个值生成当前值
IntStream.iterate(...),注意这个iterate方法不是IntStream独有的方法了,别的类也可能有。该方法可以根据上一个元素来来生成当前元素。比如我现在想要一个奇数序列,如何用iterate方法生成呢?
package com.hanserwei.mydemo.stream;
import java.util.stream.IntStream;
public class GenerateTest2 {
public static void main(String[] args) {
//IntStream.iterate
IntStream.iterate(1, x -> x + 2)
.limit(5) //截取10个
.forEach(System.out::print);
}
}
注意这样的流必须截断,不然就是无限流。也可以这样截断:
package com.hanserwei.mydemo.stream;
import java.util.stream.IntStream;
public class GenerateTest2 {
public static void main(String[] args) {
// IntStream.iterate
IntStream.iterate(1, x -> x < 10, x -> x + 2)
.forEach(System.out::print);
}
}
第二个参数就是继续生成条件。
输出结果:
13579
可以用来生成比较复杂的序列,比如斐波那契数列,但是不能用IntStream:
package com.hanserwei.mydemo.stream;
import java.util.stream.Stream;
public class GenerateTest3 {
public static void main(String[] args) {
System.out.println("使用数组记录状态(修正版):");
// 使用 Stream.iterate 而不是 IntStream.iterate
Stream.iterate(new int[]{0, 1},
// 谓词,用于判断是否继续 (Java 9+)
// 防止整数溢出
arr -> arr[0] >= 0,
// 迭代函数:[a, b] -> [b, a+b]
arr -> new int[]{arr[1], arr[0] + arr[1]})
.limit(10) // 取前10个
// 流中的元素是 int[], 我们需要的是第一个数字
// 使用 mapToInt 转换回 IntStream 以获得更好的性能
.mapToInt(arr -> arr[0])
.forEach(System.out::println);
}
}
输出:
0
1
1
2
3
5
8
13
21
34
不依赖上一个值生成当前值
IntStream.generate(...)这个方法就不用依赖上一个元素,直接生成。比如生成一个随机数序列:
package com.hanserwei.mydemo.stream;
import java.util.concurrent.ThreadLocalRandom;
import java.util.stream.Stream;
public class GenerateTest4 {
public static void main(String[] args) {
// IntStream. generate
Stream.generate(() -> ThreadLocalRandom.current().nextInt(10))
.limit(10)
.forEach(x -> System.out.print(x + " "));
}
}
输出:
9 6 8 2 6 5 1 9 3 4
和iterate相比最大的区别就是不用传入元素。当然如果你只是要生成一个随机数序列流,完全可以使用以下方法,更简单:
package com.hanserwei.mydemo.stream;
import java.util.concurrent.ThreadLocalRandom;
public class RandomSerial {
public static void main(String[] args) {
ThreadLocalRandom.current().ints(5,0,100)
.forEach(System.out::println);
}
}
老规矩,这个也是左闭右开的区间,第一个参数表示生成几个,后面两个参数是左右区间。结果如下:
26
65
8
17
4
查找与判断
查找
-
filter(Predicate p).findAny()这个就是找到任意一个元素就返回,在串行流的情况下,这个方法和findFirst没有啥区别,如果是并行流,那么才会有区别。至于并行流,后面会讲。package com.hanserwei.mydemo.stream; import java.util.stream.IntStream; public class FindTest3 { public static void main(String[] args) { // 使用并行流,来区别findAny和findFirst System.out.println("使用并行流:"); //findAny IntStream.range(0, 1000000) .parallel() // <--- 关键点1:并行处理 .filter(i -> i % 2 == 0) .findAny() // <--- 关键点2:查找任意一个 .ifPresent(System.out::println); //findFirst IntStream.range(0, 1000000) .parallel() // <--- 关键点1:并行处理 .filter(i -> i % 2 == 0) .findFirst() // <--- 关键点3:查找第一个 .ifPresent(System.out::println); } }-
行为:
findAny()的设计目标就是为了在并行计算中获得最佳性能。它被允许返回流中任何一个满足条件的元素,而不需要关心它是不是“第一个”。 -
在您的代码中: 当使用
.parallel()时,IntStream会被分成多个数据块,交给不同的线程去处理。- 可能线程A处理 0-250000
- 可能线程B处理 250001-500000
- 可能线程C处理 500001-750000
- ...等等
哪个线程最先找到一个偶数是不确定的,这取决于CPU调度、线程负载等多种因素。可能线程C最先开始工作,并找到了
500002这个偶数,它就可以立即将这个结果返回,而整个流操作就可以结束了,无需再等待其他线程。 -
结果的不确定性: 正因为这种“谁先找到就返回谁”的策略,
findAny()在并行流上多次运行的结果可能是不同的。第一次可能打印500002,第二次可能打印2400,第三次也可能打印0(如果处理第一个数据块的线程恰好最快)。
findAny()的输出是一个不确定的偶数,多次运行代码,可能会看到不同的输出结果。 -
-
filter(Predicate p).findFirst()返回第一个满足条件的元素,通常和filter一起使用。比如我要返回流里第一个偶数,代码如下:package com.hanserwei.mydemo.stream; import java.util.stream.IntStream; public class FindTest1 { public static void main(String[] args) { IntStream intStream = IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9); System.out.println(intStream.filter(x -> (x & 1) == 0).findFirst()); } }输出结果:
OptionalInt[2]注意:因为我们
findFirst可能找不到结果,我们要把存在和不存在两个情况都描述出来我们就得使用OptionalInt。如果想在找不到情况下返回一个特定的值,那么就在后面加上.orElse()来指定。也可以使用ifPresent()来对找到的值进行处理。package com.hanserwei.mydemo.stream; import java.util.stream.IntStream; public class FindTest2 { public static void main(String[] args) { IntStream intStream1 = IntStream.of(1, 3, 5, 7, 9); IntStream intStream2 = IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9); IntStream intStream3 = IntStream.of(1, 3, 5, 7, 9); System.out.println(intStream1.filter(x -> (x & 1) == 0).findFirst().orElse(-1)); intStream2.filter(x -> (x & 1) == 0).findFirst().ifPresent(System.out::println); intStream3.filter(x -> (x & 1) == 0).findFirst().ifPresent(System.out::println); } }输出:
-1 2如果没有找到,那么
ifPresent啥也不会做。行为:
findFirst()的语义是明确的:返回流中遇到的第一个元素。这个“第一”是根据流的原始顺序(encounter order)来定义的。在代码中: 在刚开始的代码中
IntStream.range(0, 1000000)创建了一个有序的数字流 (0, 1, 2, ...)。即使您使用了.parallel(),findFirst()的契约依然有效。它必须返回这个有序流中第一个满足i % 2 == 0的元素。这个元素永远是 0。并行流下的代价: 为了保证返回的是第一个,即使在并行环境下,流框架也必须进行额外的协调工作。可能某个线程已经处理到了数字
50000并发现它是一个偶数,但它不能立即返回,因为它不知道其他线程是否正在处理一个更靠前的偶数(比如 0, 2, 4...)。这可能会牺牲并行带来的性能优势。
判断
-
anyMatch(Predicate p)只要流中的元素有一个满足条件就返回true,剩下的不用判断。package com.hanserwei.mydemo.stream; import java.util.stream.IntStream; public class MatchTest1 { public static void main(String[] args) { IntStream intStream = IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9); //anyMatch System.out.println(intStream.anyMatch(x -> (x & 1) == 0)); } }输出:
true -
allMatch(Predicate p)流中所有元素都必须满足条件才能返回true,一旦发现一个不满足直接返回false。package com.hanserwei.mydemo.stream; import java.util.stream.IntStream; public class MatchTest1 { public static void main(String[] args) { IntStream intStream = IntStream.of(1, 2, 3, 4, 5, 6, 7, 8, 9); //allMatch System.out.println(intStream.allMatch(x -> (x & 1) == 0)); } }输出:
false -
noneMatch(Predicate p)所有元素都不满足条件的情况下返回true,否则就返回flase。package com.hanserwei.mydemo.stream; import java.util.stream.IntStream; public class MatchTest1 { public static void main(String[] args) { IntStream intStream = IntStream.of(1, 3, 5); // noneMatch System.out.println(intStream.noneMatch(x -> (x & 1) == 0)); } }输出:
true
去重和排序
去重
如果我们想把流中的重复元素去重,那么可以调用distinct方法。比较简单直接看代码:
package com.hanserwei.mydemo.stream;
import java.util.stream.IntStream;
public class DistinctTest {
public static void main(String[] args) {
IntStream intStream = IntStream.of(1, 1, 1, 1, 2, 1, 2, 3, 3, 3, 4, 4, 5, 6);
intStream.distinct().forEach(System.out::print);
}
}
输出:
123456
排序
如果我们要对流中的对象进行排序,那么也是可以的。直接看例子把:
package com.hanserwei.mydemo.stream;
import java.util.Comparator;
import java.util.stream.Stream;
public class SortedTest1 {
public static void main(String[] args) {
// 排序
Stream.of(
new Hero("令狐冲", 90),
new Hero("风清扬", 98),
new Hero("独孤求败", 100),
new Hero("方证", 92),
new Hero("东方不败", 98),
new Hero("冲虚", 90),
new Hero("向问天", 88),
new Hero("任我行", 92),
new Hero("不戒", 88)
).sorted(Comparator.comparingInt(h -> h.strength))
.forEach(System.out::println);
}
record Hero(String name, int strength) {
}
}
输出结果:
Hero[name=向问天, strength=88]
Hero[name=不戒, strength=88]
Hero[name=令狐冲, strength=90]
Hero[name=冲虚, strength=90]
Hero[name=方证, strength=92]
Hero[name=任我行, strength=92]
Hero[name=风清扬, strength=98]
Hero[name=东方不败, strength=98]
Hero[name=独孤求败, strength=100]
注意:这里
sorted可以接收一个比较器,从而实现自定义排序。
化简
化简是指两两合并,最好只剩一个,适合用于,最大值,最小值,求和,求个数... ...
使用reduce方法,该方法有三个重载方法
-
reduce((p,x)->r)其中p是上次合并的结果,x是当前元素,r是本次合并的结果。直接看代码实例:
package com.hanserwei.mydemo.stream; import java.util.stream.Stream; public class ReduceTest1 { public static void main(String[] args) { /* 化简:两辆合并,只保留一个 适合:最大值,最小值,求和,求个数。。。 .reduce((p,x)->r) p:上一次结果,x:当前元素,r:结果 .reduce(init,(p,x)->r) .reduce(init,(p,x)->r,(r1,r2)->r) */ // 找出武力值最高的那个 Stream.of( new Hero("令狐冲", 90), new Hero("风清扬", 98), new Hero("独孤求败", 100), new Hero("方证", 92), new Hero("东方不败", 98), new Hero("冲虚", 90), new Hero("向问天", 88), new Hero("任我行", 92), new Hero("不戒", 88) ).reduce((p, x) -> p.strength() > x.strength() ? p : x) .ifPresent(System.out::println); } record Hero(String name, int strength) { } }输出:
Hero[name=独孤求败, strength=100]注意:
reduce之后的结果也是Optional,所以后面可以加一个ifPresent来选择性消费,即有就消费,没有就算了。 -
reduce(init,(p,x)->r)这个重载方法会给定一个初始值,然后再两两比较。直接看代码:package com.hanserwei.mydemo.stream; import java.util.stream.Stream; public class ReduceTest1 { public static void main(String[] args) { /* 化简:两辆合并,只保留一个 适合:最大值,最小值,求和,求个数。。。 .reduce((p,x)->r) p:上一次结果,x:当前元素,r:结果 .reduce(init,(p,x)->r) init:初始值,p:上上次结果,x:当前元素,r:结果 .reduce(init,(p,x)->r,(r1,r2)->r) */ // 找出武力值最高的那个 Stream<Hero> heroStream = Stream.of( new Hero("令狐冲", 90), new Hero("风清扬", 98), new Hero("独孤求败", 100), new Hero("方证", 92), new Hero("东方不败", 98), new Hero("冲虚", 90), new Hero("向问天", 88), new Hero("任我行", 92), new Hero("不戒", 88) ); Hero reduced = heroStream.reduce(new Hero("五未", -1), (p, x) -> p.strength > x.strength ? p : x); System.out.println(reduced); } record Hero(String name, int strength) { } }输出:
Hero[name=独孤求败, strength=100]此时就算,流中无元素,也会输出你预设的值那个值,所有该方法返回值不用
Optional包裹。再来个例子我要统计这里面的
Hero的个数:package com.hanserwei.mydemo.stream; import java.util.stream.Stream; public class ReduceTest1 { public static void main(String[] args) { /* 化简:两辆合并,只保留一个 适合:最大值,最小值,求和,求个数。。。 .reduce((p,x)->r) p:上一次结果,x:当前元素,r:结果 .reduce(init,(p,x)->r) init:初始值,p:上上次结果,x:当前元素,r:结果 */ // 求高手总数 Stream<Hero> heroStream = Stream.of( new Hero("令狐冲", 90), new Hero("风清扬", 98), new Hero("独孤求败", 100), new Hero("方证", 92), new Hero("东方不败", 98), new Hero("冲虚", 90), new Hero("向问天", 88), new Hero("任我行", 92), new Hero("不戒", 88) ); Integer sum = heroStream.map(hero -> 1).reduce(0, Integer::sum); System.out.println(sum); } record Hero(String name, int strength) { } }输出:
9先用
map把Hero映射为数字1,然后在用reduce方法,给定一个初始值,防止结果变成Optional类型,然后把映射后的元素,两两相加得出结果。当然,对应求最大值,最小值这些简单操作,有更简单的操作:
package com.hanserwei.mydemo.stream; import java.util.Comparator; import java.util.stream.Stream; public class ReduceTest2 { public static void main(String[] args) { // 求高手总数 Hero[] heroes = { new Hero("令狐冲", 90), new Hero("风清扬", 98), new Hero("独孤求败", 100), new Hero("方证", 92), new Hero("东方不败", 98), new Hero("冲虚", 90), new Hero("向问天", 88), new Hero("任我行", 92), new Hero("不戒", 88) }; //求高手总数 long count = Stream.of(heroes).count(); System.out.println(count); //求高手武力最高值 Stream.of(heroes).max(Comparator.comparingInt(Hero::strength)).ifPresent(System.out::println); //求高手武力最低值 Stream.of(heroes).min(Comparator.comparingInt(Hero::strength)).ifPresent(System.out::println); //求所有英雄的武力值之和 int sum = Stream.of(heroes).mapToInt(Hero::strength).sum(); System.out.println(sum); //求所有英雄的武力值平均值 Stream.of(heroes).mapToInt(Hero::strength).average().ifPresent(System.out::println); } record Hero(String name, int strength) { } }输出:
9 Hero[name=独孤求败, strength=100] Hero[name=向问天, strength=88] 836 92.88888888888889 -
reduce(init,(p,x)->r,(r1,r2)->r)
收集
使用collect方法,把元素收集到一个容器里。直接看例子吧:
package com.hanserwei.mydemo.stream;
import java.util.ArrayList;
import java.util.stream.Stream;
public class CollectTest1 {
/*
收集:把元素收集到一个容器中
.collect(()->c,(c,x)-> void)
()->c :第一个无参函数Supplier,返回一个收集容器c,作用是创建一个收集容器。
(c,x)-> void :第二个BiConsumer,作用是把元素x收集到收集容器c中。
其实还有第三个参数,但暂时先不管,后面再说。但如果传null会报空指针
第三个参数也是BiConsumer,直接传一个空操作的进去。
*/
public static void main(String[] args) {
Stream<String> stream = Stream.of("A", "B", "C", "D", "E", "F", "G");
ArrayList<String> arrayList = stream
.collect(ArrayList::new, ArrayList::add, (a, b) -> {});
System.out.println(arrayList);
}
}
输出:
[A, B, C, D, E, F, G]
这个容器可以是很多种,比如常见的Set,Map,以及字符串,都是可以的。看代码:
package com.hanserwei.mydemo.stream;
import java.util.HashSet;
import java.util.stream.Stream;
public class CollectTest2 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "东方不败", "冲虚", "向问天");
HashSet<String> hashSet = stream.collect(HashSet::new, HashSet::add,(a,b)->{});
System.out.println(hashSet);
}
}
输出:
[令狐冲, 冲虚, 向问天, 任我行, 方证, 独孤求败, 东方不败, 不戒, 风清扬]
如果要保持顺序
package com.hanserwei.mydemo.stream;
import java.util.LinkedHashSet;
import java.util.stream.Stream;
public class CollectTest2 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "东方不败", "冲虚", "向问天");
LinkedHashSet<String> linkedHashSet = stream.collect(LinkedHashSet::new, LinkedHashSet::add, (a, b) -> {});
System.out.println(linkedHashSet);
}
}
输出:
[令狐冲, 风清扬, 独孤求败, 方证, 东方不败, 冲虚, 向问天, 任我行, 不戒]
如果使用Map呢?
package com.hanserwei.mydemo.stream;
import java.util.HashMap;
import java.util.Map;
import java.util.stream.Stream;
public class CollectTest2 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "东方不败", "冲虚", "向问天");
HashMap<String, Integer> hashMap = stream.collect(HashMap::new, (m, v) -> m.put(v, 1), (a, b) -> {
});
for (Map.Entry<String, Integer> stringIntegerEntry : hashMap.entrySet()) {
System.out.print(stringIntegerEntry.getKey() + " ");
}
}
}
输出:
令狐冲 冲虚 向问天 任我行 方证 独孤求败 东方不败 不戒 风清扬
其实collect还有一个一个参数的重载方法,参数是一个collector,即:传入一个收集器对象。还是来看代码例子:
Java里有很多预制的收集器,都在一个叫Collectors的类下:
这些静态方法,用于创建各种各样的收集器。
比如我想收集元素到一个List中,那么我可以这样做:
package com.hanserwei.mydemo.stream;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class CollectTest3 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "东方不败", "冲虚", "向问天");
List<String> list = stream.collect(Collectors.toList());
System.out.println(list);
}
}
输出:
[令狐冲, 风清扬, 独孤求败, 方证, 东方不败, 冲虚, 向问天, 任我行, 不戒, 东方不败, 冲虚, 向问天]
如果要收集到一个Set?
package com.hanserwei.mydemo.stream;
import java.util.Set;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class CollectTest3 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "东方不败", "冲虚", "向问天");
Set<String> set = stream.collect(Collectors.toSet());
System.out.println(set);
}
}
输出:
[令狐冲, 冲虚, 向问天, 任我行, 方证, 独孤求败, 东方不败, 不戒, 风清扬]
收集到StringBuilder里
package com.hanserwei.mydemo.stream;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class CollectTest4 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "东方不败", "冲虚", "向问天");
String string = stream.collect(Collectors.joining());
System.out.println(string);
}
}
输出:
令狐冲风清扬独孤求败方证东方不败冲虚向问天任我行不戒东方不败冲虚向问天
收集到StringJoiner里
package com.hanserwei.mydemo.stream;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class CollectTest4 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "东方不败", "冲虚", "向问天");
String string = stream.collect(Collectors.joining("*"));
System.out.println(string);
}
}
输出:
令狐冲*风清扬*独孤求败*方证*东方不败*冲虚*向问天*任我行*不戒*东方不败*冲虚*向问天
注意:收集到
StringBuilder和StringJoiner虽然方法调的是同一个,但是它们底层实现不一样,一个用到StringBuilder一个用的是StringJoiner。这里注意区分。
至于收集到Map这个稍微麻烦一点,还是直接看代码:
package com.hanserwei.mydemo.stream;
import java.util.Map;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class CollectTest5 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒");
Map<String, Integer> map = stream.collect(Collectors.toMap(x -> x, x -> x.length()));
for (Map.Entry<String, Integer> stringIntegerEntry : map.entrySet()) {
System.out.println(stringIntegerEntry.getKey()+" "+stringIntegerEntry.getValue());
}
}
}
输出:
令狐冲 3
冲虚 2
向问天 3
任我行 3
方证 2
独孤求败 4
东方不败 4
不戒 2
风清扬 3
注意:
toMap方法至少需要两个参数,两个都是Function,一个叫keyMapper,另一个叫valueMapper。这但是这个收集器不是很好用,因为它不能去重,比如我流中两个相同的元素都要为键,按理说,应该值覆盖就行了,但是这里直接抛异常!除非你传输第三个参数,一个BinaryOperator来手动指定哪个元素保留。package com.hanserwei.mydemo.stream; import java.util.Map; import java.util.stream.Collectors; import java.util.stream.Stream; public class CollectTest5 { public static void main(String[] args) { Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "令狐冲"); Map<String, Integer> map = stream.collect(Collectors.toMap(x -> x, x -> x.length(), (existing, replacement) -> existing)); for (Map.Entry<String, Integer> stringIntegerEntry : map.entrySet()) { System.out.println(stringIntegerEntry.getKey() + " " + stringIntegerEntry.getValue()); } } }
但是我们需要分组的话,我们也不用toMap来分组,而是直接用groupingBy方法来分组。
package com.hanserwei.mydemo.stream;
import java.util.Arrays;
import java.util.List;
import java.util.Map;
import java.util.stream.Collectors;
import java.util.stream.Stream;
public class CollectTest6 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "令狐冲");
/*
按名字长度分组
Map
3:new ArrayList(.....)
4:new ArrayList(.....)
2:new ArrayList(.....)
*/
Map<Integer, List<String>> map = stream.collect(Collectors.groupingBy(String::length, Collectors.toList()));
for (Map.Entry<Integer, List<String>> integerListEntry : map.entrySet()) {
System.out.println(integerListEntry.getKey() + ":" + Arrays.toString(integerListEntry.getValue().toArray()));
}
}
}
输出:
2:[方证, 冲虚, 不戒]
3:[令狐冲, 风清扬, 向问天, 任我行, 令狐冲]
4:[独孤求败, 东方不败]
groupingBy第一个参数,需要指定分类的标准,该标准作为返回值Map的键,第二个参数也需要一个收集器,用于收集符合条件的元素。
Stream流-下游收集器
下游收集器其实就是我们前面那个groupingBy的第二个参数,就是下游收集器,可以和groupingBy配合的下游收集器很多。我列个表格,你们可以自己去尝试一些。
| 方法/函数 | 描述 |
|---|---|
mapping(x -> y, dc) | 将 x 转换为 y, 用下游收集器 dc 收集 |
flatMapping(x -> substream, dc) | 将 x 转换为 substream, 用下游收集器 dc 收集 |
filtering(x -> boolean, dc) | 过滤后, 用下游收集器 dc 收集 |
counting() | 求个数 |
minBy((a, b) -> int) | 求最小 |
maxBy((a, b) -> int) | 求最大 |
summingInt(x -> int) | 转 int 后求和 |
averagingInt(x -> int) | 转 int 后求平均 |
reducing(init, (p, x) -> r) | init 初始值, 用上次结果 p 和当前元素 x 生成本次结果 r |
Stream流-基本流
基本流有三种,根据流中的元素类型区分,一共三种IntStream、LongStream以及DoubleStream。普通流中的方法,基本流也都有,而且基本流还有一些特有的方法。
以IntStream流为例,其余的基本流也类似。
| 方法 | 描述 |
|---|---|
intstream.mapToObj(int -> obj) | 转换为 obj 流 |
intstream.boxed() | 转换为 Integer 流 |
intstream.sum() | 求和 |
intstream.min() | 求最小值, 返回 Optional |
intstream.max() | 求最大值, 返回 Optional |
intstream.average() | 求平均值, 返回 Optional |
intstream.summaryStatistics() | 综合 count sum min max average |
示例代码:
package com.hanserwei.mydemo.stream;
import java.util.IntSummaryStatistics;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class EffectiveTest1 {
public static void main(String[] args) {
IntStream intStream1 = IntStream.of(97, 98, 99, 100);
IntStream intStream2 = IntStream.of(97, 98, 99, 100);
IntStream intStream3 = IntStream.of(97, 98, 99, 100);
IntStream intStream4 = IntStream.of(97, 98, 99, 100);
IntStream intStream5 = IntStream.of(97, 98, 99, 100);
IntStream intStream6 = IntStream.of(97, 98, 99, 100);
IntStream intStream7 = IntStream.of(97, 98, 99, 100);
// 转换为对象
Stream<String> stringStream = intStream1.mapToObj(Character::toString);
stringStream.forEach(System.out::println);
// 转换为包装类
Stream<Integer> integerStream = intStream2.boxed();
integerStream.forEach(System.out::println);
// 求和
int sum = intStream3.sum();
System.out.println(sum);
// 求最大值
intStream4.max().ifPresent(System.out::println);
// 求最小值
intStream5.min().ifPresent(System.out::println);
// 求平均值
intStream6.average().ifPresent(System.out::println);
// 综合count,sum, average,max,min
IntSummaryStatistics statistics = intStream7.summaryStatistics();
System.out.println(statistics.getMax());
System.out.println(statistics.getMin());
System.out.println(statistics.getAverage());
System.out.println(statistics.getSum());
}
}
输出:
a
b
c
d
97
98
99
100
394
100
97
98.5
100
97
98.5
394
普通对象流也可以转换为基本流
| 转换 |
|---|
stream.map(x -> y) |
stream.flatMap(x -> substream) |
stream.mapMulti((x, consumer) -> void) |
stream.mapToInt(x -> int) |
stream.mapToLong(x -> long) |
stream.mapToDouble(x -> double) |
package com.hanserwei.mydemo.stream;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class EffectiveTest2 {
public static void main(String[] args) {
Stream<Hero> heroStream = Stream.of(
new Hero("令狐冲", 90),
new Hero("风清扬", 98));
IntStream intStream = heroStream.mapToInt(Hero::strength);
intStream.forEach(System.out::println);
}
record Hero(String name, int strength) {
}
}
输出:
90
98
Stream流-特性
流的两个特性,一次使用和两类操作。
一次使用,是指流中的元素只能使用一次,不能多次使用。
package com.hanserwei.mydemo.stream;
import java.util.stream.Stream;
public class SummaryTest1 {
public static void main(String[] args) {
Stream<String> stream = Stream.of("令狐冲", "风清扬", "独孤求败", "方证", "东方不败", "冲虚", "向问天", "任我行", "不戒", "令狐冲");
stream.forEach(System.out::println);
// stream.forEach(System.out::println); //报错!
}
}
两类操作是指中间操作和终结操作,看例子:
package com.hanserwei.mydemo.stream;
import java.util.stream.Stream;
public class SummaryTest2 {
public static void main(String[] args) {
Stream<Integer> integerStream = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
integerStream.map(x -> x + 1).filter(x -> x > 5).forEach(System.out::println);
}
}
上述例子中,map和filter都是中间操作,forEach是终结操作。对于所有的中间操作,它们都是lazy的,终结操作都是eager的。可以把流想象为若干水滴,那么lazy的操作都是直接中间接的水管,而eager的操作就是那个阀门,它就可以控制这个水是不是要流下来。或者想象为流水线,中间操作都是对流进行加工操作,终结操作是直接决定你这个产品最后的下场是啥。而且终结操作只有一次,中间操作不限定次数。
并行流
我们之前接触的流都是串行流,所谓串行流,底层都是单线程的。而并行流,底层使用的是多线程来处理数据。并行流的好处就是处理数据的速度会很快。但是前提要用对。用错了就完蛋流。
转换为并行流也非常简单,使用一个parallel就可以直接转换为并行流。来看一下代码实例把:
package com.hanserwei.mydemo.stream;
import java.util.List;
import java.util.stream.Stream;
public class parallelStreamTest1 {
public static void main(String[] args) {
List<String> list = Stream.of("1", "2", "3", "4", "5", "6", "7", "8", "9", "10")
.parallel()
.toList();
System.out.println(list);
}
}
输出:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
单单从输出来看好像和串行流没啥区别,这个时候就得冲进去看源码了。
或者我们写一个自定义的收集器,来便于我们调试。
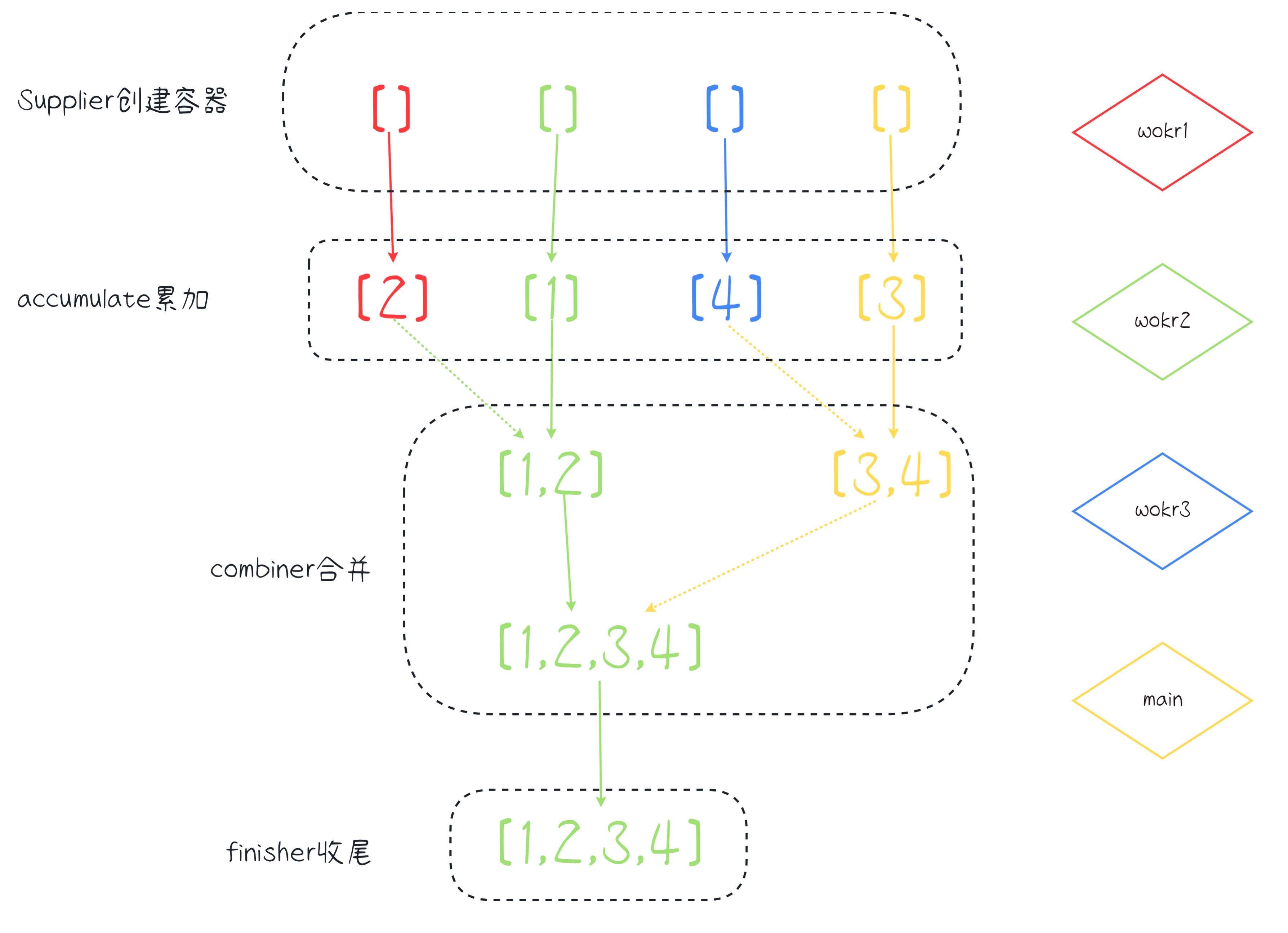
我们可以是用Collector的of静态方法,快速构造一个收集器,一个收集器要有四个逻辑以及1个特性:
- 如何创建容器
- 如何把元素加入容器
- 多线程下可能会有多个容器,那么就需要把多个容器收集的元素合并起来,即如何合并两个容器之间的数据。
- 收尾工作,对收集好的容器做最好的处理
- 特性:是否支持并发?是否需要收尾工作?是否保证收集顺序?
实例代码:
package com.hanserwei.mydemo.stream;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collector;
import java.util.stream.Stream;
public class parallelStreamTest1 {
public static void main(String[] args) {
List<Integer> collect = Stream.of(1, 2, 3, 4)
.parallel()
.collect(Collector.of(
() -> {
System.out.printf("%-12s %s%n", simple(), "create");
return new ArrayList<Integer>();
},// 1.如何创建容器
(list, x) -> {
List<Integer> old = new ArrayList<>(list);
list.add(x);
System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list);
},// 2.如何向容器添加数据
(list1, list2) -> {
List<Integer> old = new ArrayList<>(list1);
list1.addAll(list2);
System.out.printf("%-12s %s.add(%s)=>%s%n", simple(), old, list2, list1);
return list1;
},// 3.如何合并两个容器的数据
list ->{
System.out.printf("%-12s finish: %s=>%s%n", simple(), list, list);
return list;
}// 4.收尾
//5.特性:容器不支持并发,需要收尾,要保证收集顺序
));
System.out.println(collect);
}
private static String simple() {
String name = Thread.currentThread().getName();
int idx = name.indexOf("worker");
if (idx > 0) {
return name.substring(idx);
}
return name;
}
}
输出:
main create
main [].add(3)=>[3]
worker-2 create
worker-1 create
worker-1 [].add(2)=>[2]
worker-3 create
worker-3 [].add(4)=>[4]
worker-2 [].add(1)=>[1]
worker-3 [3].add([4])=>[3, 4]
worker-2 [1].add([2])=>[1, 2]
worker-2 [1, 2].add([3, 4])=>[1, 2, 3, 4]
main finish: [1, 2, 3, 4]=>[1, 2, 3, 4]
[1, 2, 3, 4]
可以看到确实是多线程的,主线程,work-1、work-2、以及work-3都create了一个容器。然后每个线程一起收集元素,最后合并容器。
如果我们去调parallel那么结果会如何呢?
package com.hanserwei.mydemo.stream;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collector;
import java.util.stream.Stream;
public class parallelStreamTest1 {
public static void main(String[] args) {
List<Integer> collect = Stream.of(1, 2, 3, 4)
// .parallel()
.collect(Collector.of(
() -> {
System.out.printf("%-12s %s%n", simple(), "create");
return new ArrayList<Integer>();
},// 1.如何创建容器
(list, x) -> {
List<Integer> old = new ArrayList<>(list);
list.add(x);
System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list);
},// 2.如何向容器添加数据
(list1, list2) -> {
List<Integer> old = new ArrayList<>(list1);
list1.addAll(list2);
System.out.printf("%-12s %s.add(%s)=>%s%n", simple(), old, list2, list1);
return list1;
},// 3.如何合并两个容器的数据
list ->{
System.out.printf("%-12s finish: %s=>%s%n", simple(), list, list);
return list;
}// 4.收尾
//5.特性:容器不支持并发,需要收尾,要保证收集顺序
));
System.out.println(collect);
}
private static String simple() {
String name = Thread.currentThread().getName();
int idx = name.indexOf("worker");
if (idx > 0) {
return name.substring(idx);
}
return name;
}
}
输出:
main create
main [].add(1)=>[1]
main [1].add(2)=>[1, 2]
main [1, 2].add(3)=>[1, 2, 3]
main [1, 2, 3].add(4)=>[1, 2, 3, 4]
main finish: [1, 2, 3, 4]=>[1, 2, 3, 4]
[1, 2, 3, 4]
可以看到只有一个线程在运作。
有一点需要知道,只有在数据量大的时候才建议使用并行流,否则会适得其反,因为时间会浪费在线程的交互上面。
刚刚我们四个元素,一共用流四个线程,那么随着元素的数目变多,线程数目会变多吗?答案是不会,因为流的处理是cpu密集型的计算,理论的上限也就是是你CPU的线程树上限。以我的电脑为例:
package com.hanserwei.mydemo.stream;
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collector;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class parallelStreamTest1 {
public static void main(String[] args) {
List<Integer> collect = IntStream.rangeClosed(1, 100)
.boxed()
.parallel()
.collect(Collector.of(
() -> {
System.out.printf("%-12s %s%n", simple(), "create");
return new ArrayList<Integer>();
},// 1.如何创建容器
(list, x) -> {
List<Integer> old = new ArrayList<>(list);
list.add(x);
System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list);
},// 2.如何向容器添加数据
(list1, list2) -> {
List<Integer> old = new ArrayList<>(list1);
list1.addAll(list2);
System.out.printf("%-12s %s.add(%s)=>%s%n", simple(), old, list2, list1);
return list1;
},// 3.如何合并两个容器的数据
list ->{
System.out.printf("%-12s finish: %s=>%s%n", simple(), list, list);
return list;
}// 4.收尾
//5.特性:容器不支持并发,需要收尾,要保证收集顺序
));
System.out.println(collect);
}
private static String simple() {
String name = Thread.currentThread().getName();
int idx = name.indexOf("worker");
if (idx > 0) {
return name.substring(idx);
}
return name;
}
}
即使我流里面一共有100个元素,但是线程最多创建到work-31加上主线程一共32线程:
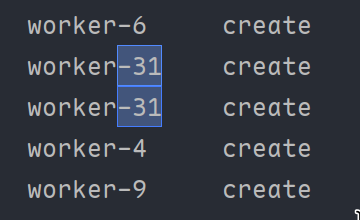
而我电脑的cpu线程数如下:

我是Linux系统,如果是Windows系统直接在任务管理器查看就行了。
最后一点,我们现在的收尾操作是把list原封不动的返回,其实我们可以在收尾的时候对list做某种转换,比如我们可以转换为不可变的list。看代码:
package com.hanserwei.mydemo.stream;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
import java.util.stream.Collector;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class parallelStreamTest1 {
public static void main(String[] args) {
List<Integer> collect = IntStream.rangeClosed(1, 4)
.boxed()
.parallel()
.collect(Collector.of(
() -> {
System.out.printf("%-12s %s%n", simple(), "create");
return new ArrayList<Integer>();
},// 1.如何创建容器
(list, x) -> {
List<Integer> old = new ArrayList<>(list);
list.add(x);
System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list);
},// 2.如何向容器添加数据
(list1, list2) -> {
List<Integer> old = new ArrayList<>(list1);
list1.addAll(list2);
System.out.printf("%-12s %s.add(%s)=>%s%n", simple(), old, list2, list1);
return list1;
},// 3.如何合并两个容器的数据
list ->{
System.out.printf("%-12s finish: %s=>%s%n", simple(), list, list);
return Collections.unmodifiableList(list);
}// 4.收尾
//5.特性:容器不支持并发,需要收尾,要保证收集顺序
));
System.out.println(collect);
//此时如果我们再添加数据,就会报错
collect.add(100);
}
private static String simple() {
String name = Thread.currentThread().getName();
int idx = name.indexOf("worker");
if (idx > 0) {
return name.substring(idx);
}
return name;
}
}
输出:
main create
worker-2 create
worker-2 [].add(1)=>[1]
worker-1 create
worker-3 create
worker-3 [].add(4)=>[4]
main [].add(3)=>[3]
worker-1 [].add(2)=>[2]
main [3].add([4])=>[3, 4]
worker-1 [1].add([2])=>[1, 2]
worker-1 [1, 2].add([3, 4])=>[1, 2, 3, 4]
main finish: [1, 2, 3, 4]=>[1, 2, 3, 4]
[1, 2, 3, 4]
Exception in thread "main" java.lang.UnsupportedOperationException
at java.base/java.util.Collections$UnmodifiableCollection.add(Collections.java:1092)
at com.hanserwei.mydemo.stream.parallelStreamTest1.main(parallelStreamTest1.java:41)
或者在收集完成后,直接换容器,比如用StringBuilder收集,最后在收尾的地方toString。
注意到我们使用的是并行流,但是容器是ArrayList,那么会有线程安全问题?答案是不会,因为ArrayList是在多个线程同时操作一个ArrayList的时候才会出现线程安全问题,但我们这里,每个线程都有它们自己的ArrayList,那么就自然不会有线程安全问题了。但是缺点也很明显。有多少线程就有多少个线程,对内存压力很大!所有有办法吗?有的兄弟,有的!
还记得最开始我们在自定义收集器的时候,最后有一个特性,我们并没有选择它的特性,所以它默认不支持并发。这个时候我们就可以手动指定它的特性了。
-
IDENTITY_FINISH不需要收尾package com.hanserwei.mydemo.stream; import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.stream.Collector; import java.util.stream.Stream; public class parallelStreamTest2 { public static void main(String[] args) { List<Integer> collect = Stream.of(1, 2, 3, 4, 5, 6, 7, 8, 9, 10) .parallel() .collect(Collector.of( () -> { System.out.printf("%-12s %s%n", simple(), "create"); return new ArrayList<Integer>(); },// 1.如何创建容器 (list, x) -> { List<Integer> old = new ArrayList<>(list); list.add(x); System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list); },// 2.如何向容器添加数据 (list1, list2) -> { List<Integer> old = new ArrayList<>(list1); list1.addAll(list2); System.out.printf("%-12s %s.add(%s)=>%s%n", simple(), old, list2, list1); return list1; },// 3.如何合并两个容器的数据 list -> { System.out.printf("%-12s finish: %s=>%s%n", simple(), list, list); return Collections.unmodifiableList(list); },// 4.收尾 // 5.特性:容器不支持并发,需要收尾,要保证收集顺序 Collector.Characteristics.IDENTITY_FINISH //不需要收尾 )); System.out.println(collect); collect.add(100); System.out.println(collect); } private static String simple() { String name = Thread.currentThread().getName(); int idx = name.indexOf("worker"); if (idx > 0) { return name.substring(idx); } return name; } }输出:
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10] [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 100]
可以看到我们不仅收集成功了,而且还没有执行收尾操作。
-
UNORDERED不需要保证顺序,CONCURRENT支持并发package com.hanserwei.mydemo.stream; import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.Vector; import java.util.stream.Collector; import java.util.stream.Stream; public class parallelStreamTest2 { public static void main(String[] args) { List<Integer> collect = Stream.of(1, 2, 3, 4,) .parallel() .collect(Collector.of( () -> { System.out.printf("%-12s %s%n", simple(), "create"); //改用线程安全的容器 return new Vector<Integer>(); },// 1.如何创建容器 (list, x) -> { //这里的这个容器只是为了调试的输出信息,实际并不参与流的工作 List<Integer> old = new ArrayList<>(list); list.add(x); System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list); },// 2.如何向容器添加数据 (list1, list2) -> { //这里的这个容器只是为了调试的输出信息,实际并不参与流的工作 List<Integer> old = new ArrayList<>(list1); list1.addAll(list2); System.out.printf("%-12s %s.add(%s)=>%s%n", simple(), old, list2, list1); return list1; },// 3.如何合并两个容器的数据 list -> { System.out.printf("%-12s finish: %s=>%s%n", simple(), list, list); return Collections.unmodifiableList(list); },// 4.收尾 // 5.特性:容器不支持并发,需要收尾,要保证收集顺序 Collector.Characteristics.IDENTITY_FINISH //不需要收尾 ,Collector.Characteristics.UNORDERED //不需要排序 ,Collector.Characteristics.CONCURRENT //支持并发 )); System.out.println(collect); collect.add(100); System.out.println(collect); } private static String simple() { String name = Thread.currentThread().getName(); int idx = name.indexOf("worker"); if (idx > 0) { return name.substring(idx); } return name; } }输出
main create main [].add(3)=>[3, 1, 2, 4] worker-2 [3].add(1)=>[3, 1, 2, 4] worker-1 [3, 1].add(2)=>[3, 1, 2, 4] worker-3 [3, 1, 2].add(4)=>[3, 1, 2, 4] [3, 1, 2, 4] [3, 1, 2, 4, 100]可以看到容器值创建了一个,其余线程都往这个容器里加元素,由于我们设置了
UNORDERED所以元素的顺序也是乱的。并且我们可以发现,没了容器合并的那个步骤,道理也很简单,因为我们至始至终只用了一个容器,所有不需要合并。但是如果我们把UNORDERED取消掉,就会有合并的操作了。还有一点不知道你们发现没有,我们打印输出的日志,每个add之后的那个list咋都是[3,1,2,4]呀。是不是代码错了?其实并没有,注意看我我们的打印语句System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list);这个操作不是原子的,啥意思呢?这个操作是要分几步才能完成,首先调用simple()然后拿old和x的值,最后去取list的值。注意:假设你主线程执行到这个地方了,准备打印日志了,那么别的线程呢?别的线程以及把元素都add进去了,你主线程再去取,就只能取到add的完的list了,而且我们这个list是同一个集合,除非你加个锁。synchronized (list) { System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list); }package com.hanserwei.mydemo.stream; import java.util.ArrayList; import java.util.Collections; import java.util.List; import java.util.Vector; import java.util.stream.Collector; import java.util.stream.Stream; public class parallelStreamTest2 { public static void main(String[] args) { List<Integer> collect = Stream.of(1, 2, 3, 4) .parallel() .collect(Collector.of( () -> { System.out.printf("%-12s %s%n", simple(), "create"); //改用线程安全的容器 return new Vector<Integer>(); },// 1.如何创建容器 (list, x) -> { List<Integer> old = new ArrayList<>(list); list.add(x); System.out.printf("%-12s %s.add(%d)=>%s%n", simple(), old, x, list); },// 2.如何向容器添加数据 (list1, list2) -> { //这里的这个容器只是为了调试的输出信息,实际并不参与流的工作 List<Integer> old = new ArrayList<>(list1); list1.addAll(list2); System.out.printf("%-12s %s.add(%s)=>%s%n", simple(), old, list2, list1); return list1; },// 3.如何合并两个容器的数据 list -> { System.out.printf("%-12s finish: %s=>%s%n", simple(), list, list); return Collections.unmodifiableList(list); },// 4.收尾 // 5.特性:容器不支持并发,需要收尾,要保证收集顺序 Collector.Characteristics.IDENTITY_FINISH //不需要收尾 // ,Collector.Characteristics.UNORDERED //不需要排序 ,Collector.Characteristics.CONCURRENT //支持并发 )); System.out.println(collect); collect.add(100); System.out.println(collect); } private static String simple() { String name = Thread.currentThread().getName(); int idx = name.indexOf("worker"); if (idx > 0) { return name.substring(idx); } return name; } }输出:
main create main [].add(3)=>[3] worker-2 create worker-1 create worker-1 [].add(2)=>[2] worker-3 create worker-2 [].add(4)=>[4] worker-2 [3].add([4])=>[3, 4] worker-3 [].add(1)=>[1] worker-3 [1].add([2])=>[1, 2] worker-3 [1, 2].add([3, 4])=>[1, 2, 3, 4] [1, 2, 3, 4] [1, 2, 3, 4, 100]实际开发中:我们用哪个呢?其实JDK的收集器是有支持并发的收集器的。
这些收集器都是类似于我们上面自己构建的收集器,使用
UNORDERED不需要保证顺序,CONCURRENT支持并发两个特性,然后收集容器使用的使用支持并发的容器,但是如果并发量太大了,这种收集器的效率会降低。会有并发冲突的风险。





