Java数据类型
本文最后更新于 2025-07-22,文章内容可能已经过时。
Java数据类型
Java是一种静态类型的语言,这就意味着所有变量必须在使用之前就声明好,也就是必须得先指定变量的类型和名称。
Java中的数据类型可以分为两大类:
-
基本数据类型
基本数据类型是Java语言操作数据的基础,包括
boolean、char、byte、short、int、long、float和double,共八种。 -
引用数据类型。
除了基本数据类型以外的类型,都是所谓的引用数据类。常见的有数组、
class,以及接口。
graph TD
A[数据类型] --> B(基本数据类型)
A --> C(引用数据类型)
B --> B1(布尔型)
B1 --> B1_1(boolean)
B --> B2(数值型)
B2 --> B2_1(整形)
B2_1 --> B2_1_1(short)
B2_1 --> B2_1_2(int)
B2_1 --> B2_1_3(long)
B2 --> B2_2(浮点型)
B2_2 --> B2_2_1(float)
B2_2 --> B2_2_2(double)
B2 --> B2_3(字节型)
B2_3 --> B2_3_1(byte)
B --> B3(字符型)
B3 --> B3_1(char)
C --> C1(数组)
C --> C2(类)
C --> C3(接口)
变量可以分为局部变量、成员变量、静态变量。
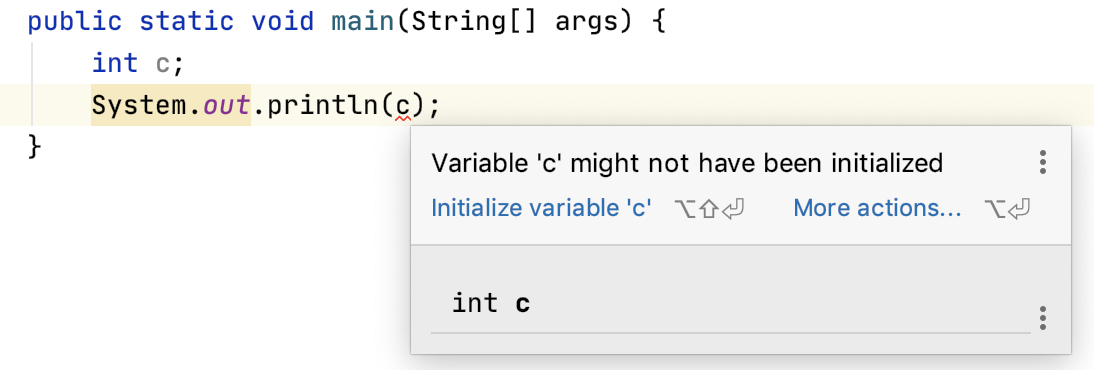
当变量是局部变量的时候,必须得先初始化,否则编译器不允许你使用它。拿int来举例吧,看下图。
当变量是成员变量或者静态变量时,可以不进行初始化,它们会有一个默认值,仍然以int为例,来看代码:
public class LocalVar {
private int a;
static int b;
public static void main(String[] args) {
LocalVar lv = new LocalVar();
System.out.println(lv.a);
System.out.println(b);
}
}
输出结果:
0
0
瞧见没,int作为成员变量时或者静态变量时的默认值是 0。那不同的基本数据类型,是有不同的默认值和占用大小的,来个表格感受下。
| 数据类型 | 默认值 | 大小 |
|---|---|---|
| boolean | false | 不确定 |
| char | ‘\u0000’ | 2字节 |
| byte | 0 | 1字节 |
| short | 0 | 2字节 |
| int | 0 | 4字节 |
| long | 0L | 8字节 |
| float | 0.0f | 4字节 |
| double | 0.0 | 8字节 |
01、比特和字节
比特币(Bitcoin)听说过吧?字节跳动(Byte Dance)听说过吧?这些名字当然不是乱起的,确实和比特、字节有关系。
1)bit(比特)
比特作为信息技术的最基本存储单位,非常小,但大名鼎鼎的比特币就是以此命名的,它的简写为小写字母“b”。
大家都知道,计算机是以二进制存储数据的,二进制的一位,就是 1 比特,也就是说,比特要么为 0 要么为 1。
2)Byte(字节)
通常来说,一个英文字符是一个字节,一个中文字符是两个字节。字节与比特的换算关系是:1 字节 = 8 比特。
在往上的单位就是 KB,并不是 1000 字节,因为计算机只认识二进制,因此是 2 的 10 次方,也就是 1024 个字节。
graph TD
A[换算单位] --> B(1 Byte = 8 bit)
A --> C(1 KB = 1024 Byte)
A --> D(1 MB = 1024 KB)
A --> E(1 GB = 1024 M)
A --> F(1 TB = 1024 GB)
02、基本数据类型
接下来我们来详细了解一下8种数据类型。
1)boolean
布尔(boolean)仅用于存储两个值:true 和 false,也就是真和假,通常用于条件的判断。代码示例:
boolean hasMoney = true;
boolean hasGirlFriend = false;
根据 Java 语言规范,boolean类型只有两个值true和false,但在语言层面,Java 没有明确规定boolean类型的大小。
我查了一下资料,发现关于boolean的大小有两种说法:
我们先来看论调一:
对于单独使用的boolean类型,JVM 并没有提供专用的字节码指令,而是使用 int 相关的指令istore来处理,那么 int 明确是 4 个字节,所以此时的 boolean 也占用 4 个字节。
对于作为数组来使用的 boolean 类型,JVM 会按照 byte 的指令来处理(bastore),那么已知 byte 类型占用 1 个字节,所以此时的boolean也占用 1 个字节。
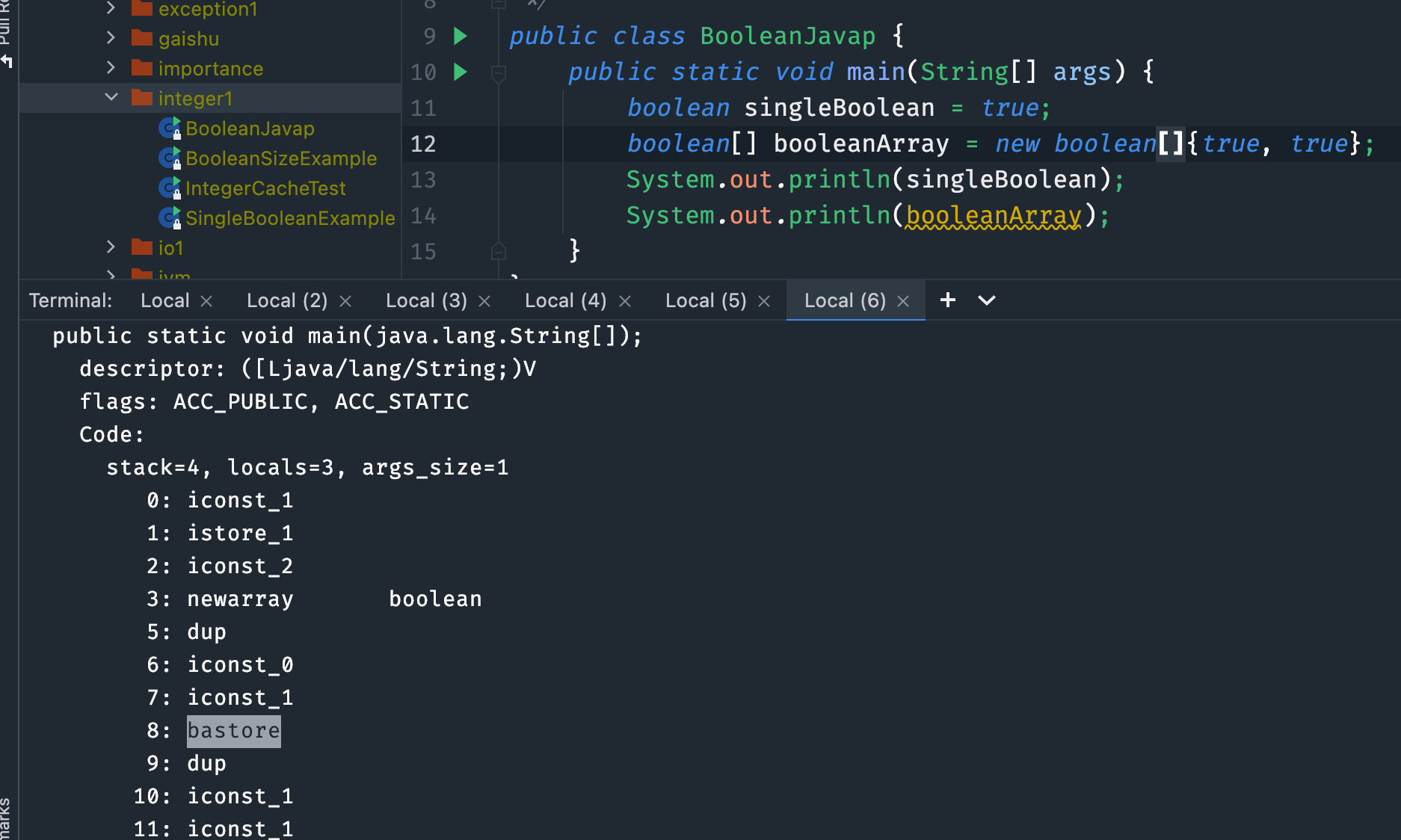
论调二:
boolean: The boolean data type has only two possible values: true and false. Use this data type for simple flags that track true/false conditions. This data type represents one bit of information, but its “size” isn’t something that’s precisely defined.
可以通过 JOL 工具打印出对象的内存布局,展示boolean单独使用和作为数组使用时在内存中的实际占用大小。
public class BooleanSizeExample {
public static void main(String[] args) {
boolean singleBoolean = true;
boolean[] booleanArray = new boolean[10];
// 分析内存占用,可以使用第三方工具如 JOL(Java Object Layout)
System.out.println("Size of single boolean: " + org.openjdk.jol.info.ClassLayout.parseInstance(singleBoolean).toPrintable());
System.out.println("Size of boolean array: " + org.openjdk.jol.info.ClassLayout.parseInstance(booleanArray).toPrintable());
}
}
运行结果如下(64 操作系统 JDK 8):
Size of single boolean: java.lang.Boolean object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) dd 20 00 f8 (11011101 00100000 00000000 11111000) (-134209315)
12 1 boolean Boolean.value true
13 3 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 3 bytes external = 3 bytes total
Size of boolean array: [Z object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 00 00 f8 (00000101 00000000 00000000 11111000) (-134217723)
12 4 (object header) 0a 00 00 00 (00001010 00000000 00000000 00000000) (10)
16 10 boolean [Z.<elements> N/A
26 6 (loss due to the next object alignment)
Instance size: 32 bytes
Space losses: 0 bytes internal + 6 bytes external = 6 bytes total
对于单个boolean变量来说:
- 对象头(Object Header占用12个字符:
- OFFSET 0 - 4:对象头的一部分,包含对象的标记字段(Mark Word),用于存储对象的哈希码、GC 状态等。
- OFFSET 4 - 8:对象头的另一部分,通常是指向类元数据的指针(Class Pointer)。
- OFFSET 8 - 12:对象头的最后一部分,包含锁状态或其他信息。
- 实际的
boolean值占用 1 个字节,也就是OFFSET 12 - 13。 - 为了满足 8 字节的对齐要求(HotSpot JVM 默认的对象对齐方式),有 3 个字节的填充。OFFSET 13 - 16。
也就是说,尽管 boolean 值本身只需要 1 个字节,但由于对象头和对齐要求,一个 boolean 在内存中占用 16 字节。
对于 boolean 数组来说:
- 对象头(Object Header) 占用了 12 个字节:
- OFFSET 0 - 4:对象头的一部分,包含对象的标记字段(Mark Word)。
- OFFSET 4 - 8:对象头的另一部分,包含指向类元数据的指针(Class Pointer)。
- OFFSET 8 - 12:对象头的最后一部分,通常包含数组的长度信息。
- 数组长度 占用了 4 个字节,此处是 10,OFFSET 12 - 16。
- 实际的
boolean数组元素,每个boolean值占用 1 个字节,总共 10 个字节,OFFSET 16 - 26。 - 为了满足 8 字节对齐要求,有 6 个字节的填充,OFFSET 26 - 32。
也就是说,每个 boolean 数组元素占用 1 个字节,加上对象头、对齐填充和数组长度,包含 10 个元素的 boolean 数组占用 32 字节。
2)byte
一个字节可以表示 $2^8$ = 256 个不同的值。由于 byte 是有符号的,它的值可以是负数或正数,其取值范围是 -128 到 127(包括 -128 和 127)。
在网络传输、大文件读写时,为了节省空间,常用字节来作为数据的传输方式。代码示例:
byte b; // 声明一个 byte 类型变量
b = 10; // 将值 10 赋给变量 b
byte c = -100; // 声明并初始化一个 byte 类型变量 c,赋值为 -100
3)short
short 的取值范围在 -32,768 和 32,767 之间,包含 32,767。代码示例:
short s; // 声明一个 short 类型变量
s = 1000; // 将值 1000 赋给变量 s
short t = -2000; // 声明并初始化一个 short 类型变量 t,赋值为 -2000
实际开发中,short 比较少用,整型用 int 就 OK。
4)int
int 的取值范围在 -2,147,483,648($-2^{31}$)和 2,147,483,647($2^{31}-1$)(含)之间。如果没有特殊需求,整型数据就用 int。代码示例:
int i; // 声明一个 int 类型变量
i = 1000000; // 将值 1000000 赋给变量 i
int j = -2000000; // 声明并初始化一个 int 类型变量 j,赋值为 -2000000
为什么 32 位的有符号整数的取值范围是从 $-2^{31}$ 到 $2^{31} - 1$ 呢?
这是因为其中一位用于表示符号(正或负),剩下的 31 位用于表示数值,这意味着其范围是 -2,147,483,648(即 $-2^{31}$)到 2,147,483,647(即 $2^{31} - 1$)。
在二进制系统中,每个位(bit)可以表示两个状态,通常是 0 和 1。对于 32 位得正二进制数,除去符号位,从右到左的每一位分别代表 $2^0$, $2^1$, $2^2$, …, $2^{30}$,这个二进制数转换为十进制就是$ 2^0$ + $2^1$ +$ 2^2$ + … +$ 2^{30}$,也就是 2,147,483,647。
5)long
long的取值范围在
-9,223,372,036,854,775,808($-2^{63}$) 和 9,223,372,036,854,775,807($2^{63} -1$)(含)之间。如果 int 存储不下,就用 long。代码示例:
long l; // 声明一个 long 类型变量
l = 100000000000L; // 将值 100000000000L 赋给变量 l(注意要加上 L 后缀)
long m = -20000000000L; // 声明并初始化一个 long 类型变量 m,赋值为 -20000000000L
为了和 int 作区分,long 型变量在声明的时候,末尾要带上大写的“L”。不用小写的“l”,是因为小写的“l”容易和数字“1”混淆。
6)float
float 是单精度的浮点数(单精度浮点数的有效数字大约为 6 到 7 位),32 位(4 字节),遵循 IEEE 754(二进制浮点数算术标准),取值范围为 1.4E-45 到 3.4E+38。float 不适合用于精确的数值,比如说金额。代码示例:
float f; // 声明一个 float 类型变量
f = 3.14159f; // 将值 3.14159f 赋给变量 f(注意要加上 f 后缀)
float g = -2.71828f; // 声明并初始化一个 float 类型变量 g,赋值为 -2.71828f
为了和 double 作区分,float 型变量在声明的时候,末尾要带上小写的“f”。不需要使用大写的“F”,是因为小写的“f”很容易辨别。
7)double
double 是双精度浮点数(双精度浮点数的有效数字大约为 15 到 17 位),占 64 位(8 字节),也遵循 IEEE 754 标准,取值范围大约 ±4.9E-324 到 ±1.7976931348623157E308。double 同样不适合用于精确的数值,比如说金额。
代码示例:
double myDouble = 3.141592653589793;
在进行金融计算或需要精确小数计算的场景中,可以使用BigDecimal类来避免浮点数舍入误差。BigDecimal可以表示一个任意大小且精度完全准确的浮点数。
在实际开发中,如果不是特别大的金额(精确到 0.01 元,也就是一分钱),一般建议乘以 100 转成整型进行处理。
8)char
char 用于表示 Unicode 字符,占 16 位(2 字节)的存储空间,取值范围为 0 到 65,535。
代码示例:
char letterA = 'A'; // 用英文的单引号包裹住。
注意,字符字面量应该用单引号(‘’)包围,而不是双引号(“”),因为双引号表示字符串字面量。
03、单精度和双精度
单精度(single-precision)和双精度(double-precision)是指两种不同精度的浮点数表示方法。
单精度是这样的格式,1 位符号,8 位指数,23 位小数。

单精度浮点数通常占用 32 位(4 字节)存储空间。数值范围大约是 ±1.4E-45 到 ±3.4028235E38,精度大约为 6 到 9 位有效数字。
双精度是这样的格式,1 位符号,11 位指数,52 为小数。
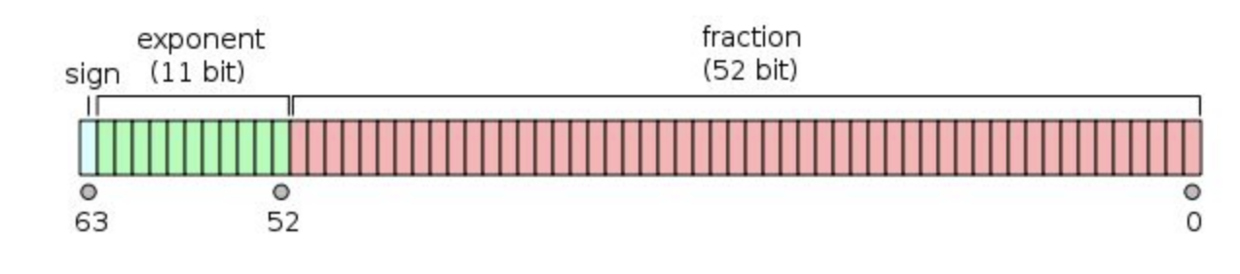
双精度浮点数通常占用 64 位(8 字节)存储空间,数值范围大约是 ±4.9E-324 到 ±1.7976931348623157E308,精度大约为 15 到 17 位有效数字。
计算精度取决于小数位(尾数)。小数位越多,则能表示的数越大,那么计算精度则越高。
一个数由若干位数字组成,其中影响测量精度的数字称作有效数字,也称有效数位。有效数字指科学计算中用以表示一个浮点数精度的那些数字。一般地,指一个用小数形式表示的浮点数中,从第一个非零的数字算起的所有数字。如 1.24 和 0.00124 的有效数字都有 3 位。
以下是确定有效数字的一些基本规则:
- 非零数字总是有效的。
- 位于两个非零数字之间的零是有效的。
- 对于小数,从左侧开始的第一个非零数字之前的零是无效的。
- 对于整数,从右侧开始的第一个非零数字之后的零是无效的。
下面是一些示例,说明如何确定有效数字:
- 1234:4 个有效数字(所有数字都是非零数字)
- 1002:4 个有效数字(零位于两个非零数字之间)
- 0.00234:3 个有效数字(从左侧开始的前两个零是无效的)
- 1200:2 个有效数字(从右侧开始的两个零是无效的)
04、int和char类型互转
int和char直接互相转换
int 和 char 之间比较特殊,可以互转,也会在以后的学习当中经常遇到。
- 可以通过强制类型转换讲整型
int转换为字符char。
int value_int = 65;
char value_char = (char) value_int;
System.out.println(value_char);
输出A(其ASCII码值可以通过整数65来表示)
- 可以使用
Character.forDigit()方法将整型 int 转换为字符 char,参数 radix 为基数,十进制为 10,十六进制为 16。
int radix = 10;
int value_int = 6;
char value_char = Character.forDigit(value_int , radix);
System.out.println(value_char );
Character 为 char 的包装器类型。我们随后会讲。
- 可以使用
int的包装器类型Integer的toString()方法+String的charAt()方法转成char。
int value_int = 1;
char value_char = Integer.toString(value_int).charAt(0);
System.out.println(value_char );
char转int
当然了,如果只是简单的 char 转 int,直接赋值就可以了。
int a = 'a';
因为发生了自动类型转换,后面会讲。
不过,如果字符本身就是数字,这种方法就行不通了。
int a = '1';
这样的话,a 的值是 49,而不是 1。因为字符 ‘1’ 的 ASCII 码是 49。
那么,怎么才能把字符 ‘1’ 转成数字 1 呢?
可以使用 Character.getNumericValue() 方法。
int a = Character.getNumericValue('1');
这样的话,a 的值就是 1 了。
除此之外,还可以使用 Character.digit() 方法。
int a = Character.digit('1', 10);
这样的话,a 的值也是 1。
因为这两个方法的内部实现都大差不差,大家可以研究一下源码。
那还有一种更直观的方法,就是 - '0' 方法。
int a = '1' - '0';
这样的话,a 的值也是 1。这是因为在 ASCII 编码和 Unicode 编码(Java 使用 Unicode 编码)中,数字字符 ‘0’ 到 ‘9’ 是连续排列的,并且它们的编码值是顺序递增的。
字符 ‘0’ 的编码值是 48,字符 ‘1’ 的编码值是 49,依此类推,字符 ‘9’ 的编码值是 57。
当从一个字符的编码值中减去字符 ‘0’ 的编码值(即 48),结果就是该字符所表示的数字值。例如,对于字符 ‘5’,其编码值是 53。计算 53 - 48 得到 5,这就是字符 ‘5’ 所表示的数字值。
05、包装器类型
包装器类型(Wrapper Types)是 Java 中的一种特殊类型,用于将基本数据类型(如 int、float、char 等)转换为对应的对象类型。
Java 提供了以下包装器类型,与基本数据类型一一对应:
- Byte(对应 byte)
- Short(对应 short)
- Integer(对应 int)
- Long(对应 long)
- Float(对应 float)
- Double(对应 double)
- Character(对应 char)
- Boolean(对应 boolean)
包装器类型允许我们使用基本数据类型提供的各种实用方法,并兼容需要对象类型的场景。例如,我们可以使用 Integer 类的 parseInt 方法将字符串转换为整数,或使用 Character 类的 isDigit 方法检查字符是否为数字,还有前面提到的 Character.forDigit() 方法。
下面是一个简单的示例,演示了如何使用包装器类型:
// 使用 Integer 包装器类型
Integer integerValue = new Integer(42);
System.out.println("整数值: " + integerValue);
// 将字符串转换为整数
String numberString = "123";
int parsedNumber = Integer.parseInt(numberString);
System.out.println("整数值: " + parsedNumber);
// 使用 Character 包装器类型
Character charValue = new Character('A');
System.out.println("字符: " + charValue);
// 检查字符是否为数字
char testChar = '9';
if (Character.isDigit(testChar)) {
System.out.println("字符是个数字.");
}
上面的示例中,我妈创建了一个Integer类型的对象integerValue并为其赋值42。然后,我妈将其值打印到控制台。
我们有一个包含数字的字符串 numberString。我们使用 Integer.parseInt() 方法将其转换为整数 parsedNumber。然后,我们将转换后的值打印到控制台。
比如说 parseInt() 用于将字符串转换为整数,这也是非常常用的一个方法,尤其是遇到“数字字符串”转整数的时候。
String text = "123";
int number = Integer.parseInt(text);
System.out.println(number);
可以简单看一下 parseInt() 的源码:
public static int parseInt(String s, int radix) throws NumberFormatException {
// 如果字符串为空或基数不在有效范围内,抛出 NumberFormatException
if (s == null || radix < Character.MIN_RADIX || radix > Character.MAX_RADIX) {
throw new NumberFormatException();
}
int result = 0; // 用于存储解析结果的变量
boolean negative = false; // 标记数字是否为负数
int i = 0, len = s.length(); // i 是字符索引,len 是字符串长度
int limit = -Integer.MAX_VALUE; // 溢出检查的上限
if (len > 0) {
char firstChar = s.charAt(0); // 获取字符串的第一个字符
if (firstChar == '-') { // 如果是负号
negative = true; // 设置负数标记
limit = Integer.MIN_VALUE; // 调整溢出上限为 Integer 的最小值
i++;
} else if (firstChar == '+') { // 如果是正号
i++; // 仅跳过,不做额外操作
}
int multmin = limit / radix; // 计算溢出检查的临界值
while (i < len) {
// 将字符转换为对应的数字值
int digit = Character.digit(s.charAt(i++), radix);
if (digit < 0 || result < multmin || result * radix < limit + digit) {
// 如果字符不是有效数字或者结果溢出,抛出 NumberFormatException
throw new NumberFormatException();
}
// 累积结果
result = result * radix - digit;
}
} else {
// 如果字符串为空,抛出 NumberFormatException
throw new NumberFormatException();
}
// 根据正负号返回最终结果
return negative ? result : -result;
}
简单解释一下:
- 空值检查:首先检查输入字符串是否为
null,如果是,则抛出NumberFormatException。 - 符号处理:检查字符串的第一个字符以确定数字的符号(正或负)。如果字符串以“-”开头,则数字为负数,以“+”或数字开头则为正数。
- 数字转换:遍历字符串中的每个字符,将字符转换为对应的数字。这是通过从字符中减去 ‘0’ 的 ASCII 值来实现的。
- 结果计算:计算最终的数字值。这是通过将每个数字乘以其位置权重(10 的幂)并累加到结果中来完成的。
- 溢出检查:在整个转换过程中,代码会检查是否有溢出的风险。如果检测到溢出,将抛出
NumberFormatException。 - 返回结果:根据数字的符号返回最终结果。
从 Java 5 开始,自动装箱(Autoboxing)和自动拆箱(Unboxing)机制允许我们在基本数据类型和包装器类型之间自动转换,无需显式地调用构造方法或转换方法(链接里会细讲)。
Integer integerValue = 42; // 自动装箱,等同于 new Integer(42)
int primitiveValue = integerValue; // 自动拆箱,等同于 integerValue.intValue()
06、引用数据类型
基本数据类型在作为成员变量和静态变量的时候有默认值,引用数据类型也有的(学完数组&字符串,以及面向对象编程后会更加清楚,这里先简单过一下)。
String是最典型的引用数据类型,所以我们就拿String类举例,看下面这段代码:
public class LocalRef {
private String a;
static String b;
public static void main(String[] args) {
LocalRef lv = new LocalRef();
System.out.println(lv.a);
System.out.println(b);
}
}
输出结果如下:
null
null
null 在 Java 中是一个很神奇的存在,在你以后的程序生涯中,见它的次数不会少,尤其是伴随着令人烦恼的“空指针异常”,也就是所谓的NullPointerException。
也就是说,引用数据类型的默认值为 null,包括数组和接口。
那你是不是很好奇,为什么数组和接口也是引用数据类型啊?
先来看数组:
int [] arrays = {1,2,3};
System.out.println(arrays);
arrays 是一个 int 类型的数组,对吧?打印结果如下所示:
[I@2d209079
[I 表示数组是 int 类型的,@ 后面是十六进制的 hashCode——这样的打印结果太“人性化”了,一般人表示看不懂!为什么会这样显示呢?查看一下 java.lang.Object 类的 toString() 方法就明白了。

数组虽然没有显式定义成一个类,但它的确是一个对象,继承了祖先类 Object 的所有方法。那为什么数组不单独定义一个类来表示呢?就像字符串 String 类那样呢?
一个合理的解释是 Java 将其隐藏了。假如真的存在一个 Array.java,我们也可以假想它真实的样子,它必须要定义一个容器来存放数组的元素,就像 String 类那样。
public final class String
implements java.io.Serializable, Comparable<String>, CharSequence {
/** The value is used for character storage. */
private final char value[];
}
数组内部定义数组?没必要的!
再来看接口:
List<String> list = new ArrayList<>();
System.out.println(list);
List是一个非常典型的接口:
public interface List<E> extends Collection<E> {}
而ArrayList是List接口的一个实现:
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{}
对于接口类型的引用变量来说,你没法直接 new 一个:

只能 new 一个实现它的类的对象——那自然接口也是引用数据类型了。
来看一下基本数据类型和引用数据类型之间最大的差别。
基本数据类型:
- 1、变量名指向具体的数值。
- 2、基本数据类型存储在栈上。
引用数据类型:
- 1、变量名指向的是存储对象的内存地址,在栈上。
- 2、内存地址指向的对象存储在堆上。
07、堆和栈
堆是堆(heap),栈是栈(stack),如果看到“堆栈”的话,请不要怀疑自己,那是翻译的错,堆栈也是栈,反正我很不喜欢“堆栈”这种叫法,容易让新人掉坑里。
堆是在程序运行时在内存中申请的空间(可理解为动态的过程);切记,不是在编译时;因此,Java 中的对象就放在这里,这样做的好处就是:
当需要一个对象时,只需要通过 new 关键字写一行代码即可,当执行这行代码时,会自动在内存的“堆”区分配空间——这样就很灵活。
栈,能够和处理器(CPU,也就是脑子)直接关联,因此访问速度更快。既然访问速度快,要好好利用啊!Java 就把对象的引用放在栈里。为什么呢?因为引用的使用频率高吗?
不是的,因为 Java 在编译程序时,必须明确的知道存储在栈里的东西的生命周期,否则就没法释放旧的内存来开辟新的内存空间存放引用——空间就那么大,前浪要把后浪拍死在沙滩上啊。
用图来表示一下,左侧是栈,右侧是堆。

举个例子。
String a = new String("我是帅帅维!")
这段代码会先在堆里创建一个我是帅帅维的字符串对象,然后再把对象的引用 a 放到栈里面。这里面还会涉及到字符串常量池,后面会讲。
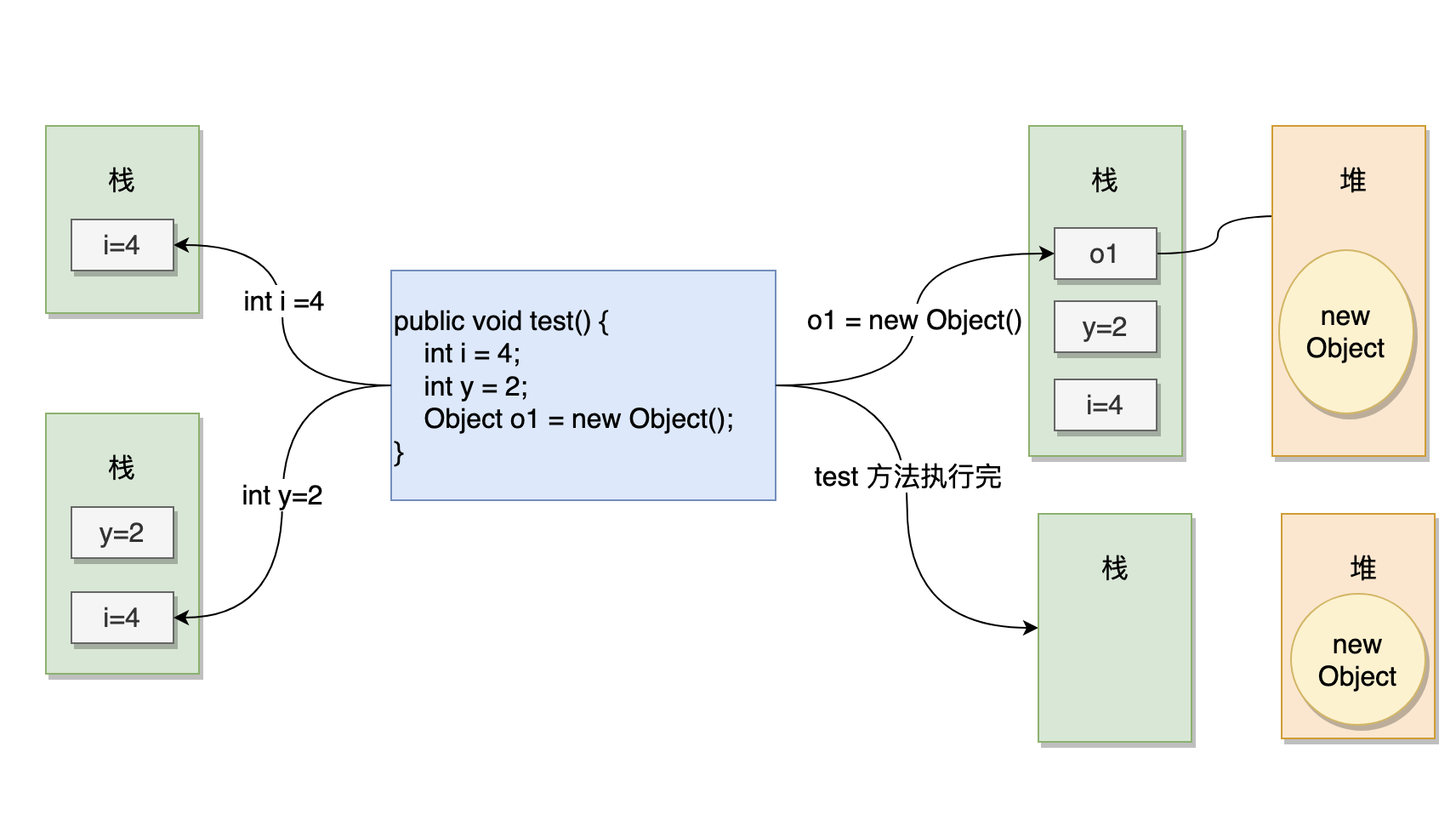
那么对于这样一段代码,有基本数据类型的变量,有引用类型的变量,堆和栈都是如何存储他们的呢?
public void test()
{
int i = 4;
int y = 2;
Object o1 = new Object();
}
我来画个图表示下。